ML Lifecycle Management Explained for Engineers

Machine learning lifecycle management is the continuous process of developing, deploying, monitoring, and refining ML models to maintain performance, compliance, and operational efficiency across every stage of a model's existence. The industry term for this discipline is MLOps, and understanding ml lifecycle management explained in full means recognizing it as a loop, not a line. Organizations like Databricks and platforms like Mlflow have made this loop the foundation of production ML in 2026. Teams that treat the lifecycle as a one-time build-and-ship process pay for it in silent model degradation, compliance gaps, and failed deployments.
What are the key stages of the ML lifecycle?
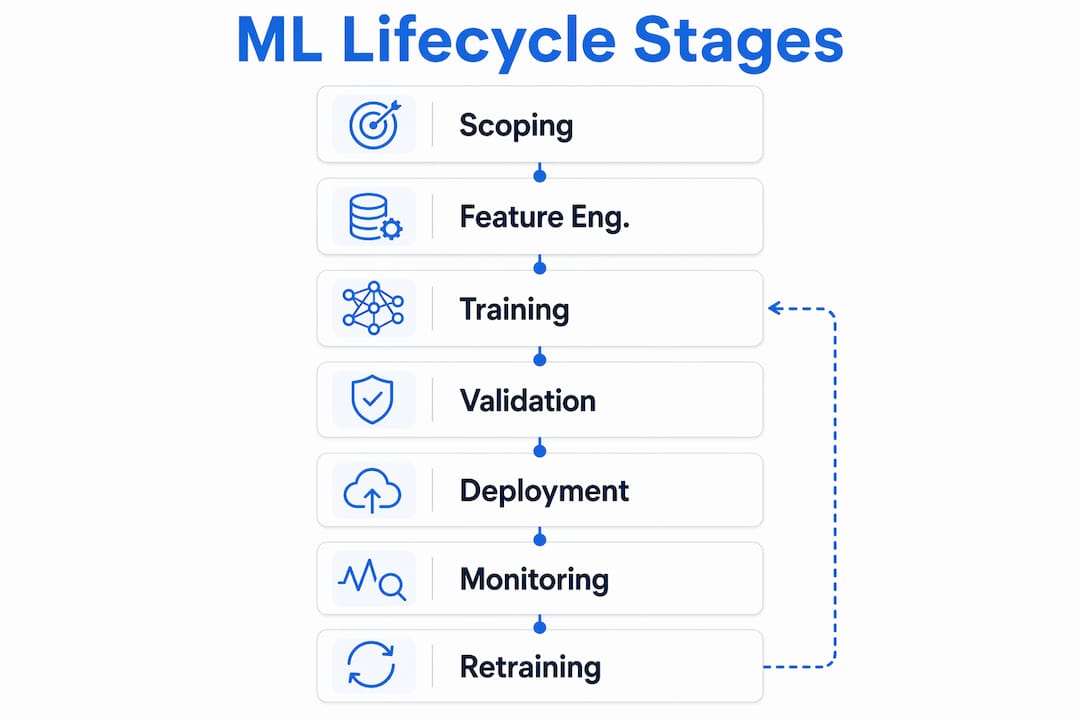
The ML lifecycle is a continuous loop of 8–10 stages grouped into three phases: development, staging, and production. Each stage feeds the next, and the output of production monitoring feeds back into development. This is what makes the machine learning lifecycle fundamentally different from traditional software delivery.
Here are the core stages in order:
- Problem scoping — Define the business objective, success metrics, and data availability before writing a single line of training code.
- Data collection and preparation — Gather raw data, handle missing values, and document sources for lineage tracking.
- Exploratory data analysis (EDA) — Profile distributions, detect outliers, and identify feature candidates.
- Feature engineering — Transform raw signals into model inputs. Feature definitions and data lineage treated as versioned artifacts prevent training-serving skew, one of the most common causes of production failure.
- Model training — Run experiments, track hyperparameters, and log metrics using experiment tracking tools.
- Validation — Evaluate offline metrics, run fairness checks, and confirm the model meets the defined success criteria.
- Model registry — Register the validated model with links to training code, dataset version, and environment config.
- Deployment — Serve the model to production traffic using a controlled rollout strategy.
- Monitoring — Track data drift, prediction drift, and ground truth feedback continuously.
- Retraining — Trigger a new training run when drift thresholds or performance degradation signals are detected.
Pro Tip: Start experiment tracking at stage one, not stage five. The lifecycle begins before training code is written, and early logging of data versions and feature definitions saves hours of debugging later.
The table below maps each phase to its primary goal and the teams most responsible:
| Phase | Stages Included | Primary Goal |
|---|---|---|
| Development | Scoping, EDA, Feature Engineering, Training | Build a validated, reproducible model |
| Staging | Validation, Model Registry | Gate quality and prepare for safe deployment |
| Production | Deployment, Monitoring, Retraining | Sustain performance and trigger corrective loops |

How do governance and observability shape effective ML lifecycle management?
Governance is not a checkpoint at the end of the machine learning model workflow. It is a property of the entire pipeline. The most reliable teams embed approval workflows, audit trails, and compliance checks directly into their MLOps pipelines so governance happens automatically on every change.
The model registry is the cornerstone of this approach. Model registries standardized as the single source of truth link each model version to its training code, dataset lineage, and environment configuration. This structure satisfies auditability requirements under frameworks like the EU AI Act and SOC 2. Without it, proving which data trained which model version becomes a manual, error-prone exercise.
Key governance practices that belong in every ML lifecycle:
- Version linking — Every model artifact in the Mlflow model registry carries a pointer to the exact dataset version and training run that produced it.
- Automated compliance checks — Automating safety and compliance checks on every pipeline change accelerates iteration without creating audit gaps.
- Drift-triggered retraining — Automated triggers fire when data or prediction drift crosses a defined threshold, removing the need for manual intervention.
- Access control — Role-based permissions on model versions prevent unauthorized promotion from staging to production.
- Approval workflows — Promotion gates between staging and production require sign-off from designated reviewers, creating a documented chain of custody.
Pro Tip: Treat MLOps pipeline automation as your compliance layer. When every stage transition runs the same automated checks, you get governance by default rather than governance by effort.
Observability in the ML lifecycle goes beyond logs and dashboards. It means you can reconstruct exactly why a model produced a given prediction at a given time, using the data version, feature values, and model version that were active at that moment. That level of traceability is what regulators expect and what incident response requires.
What are best practices for deployment and risk management?
Binary deployment, pushing a new model to 100% of traffic at once, is the highest-risk approach in the ml model deployment process. Progressive delivery methods like feature flags, champion/challenger testing, and gradual rollouts are the standard in 2026 precisely because they make failure recoverable.
Here is how a progressive deployment sequence works in practice:
- Shadow mode — Route production traffic to both the current model and the new model, but only serve the current model's predictions. Log the new model's outputs for offline comparison.
- Canary release — Shift a small percentage of live traffic (typically 5–10%) to the new model. Monitor error rates, latency, and prediction distributions.
- Champion/challenger testing — Run the new model against the current champion on a defined traffic split. Use statistical significance thresholds to declare a winner.
- Full promotion — Migrate all traffic to the new model once it clears performance gates.
- Rollback — If any gate fails, automated rollback restores the previous version without manual intervention.
| Deployment Method | Risk Level | Rollback Speed | Best Used When |
|---|---|---|---|
| Binary (all-at-once) | High | Slow, manual | Low-stakes internal tools only |
| Canary release | Medium | Fast, automated | Most production model updates |
| Champion/challenger | Low | Instant | High-stakes or regulated models |
| Shadow mode | Very low | Not needed | Validating new models pre-release |
Pro Tip: Use feature flags for gradual rollout control. They let you pause a deployment mid-rollout without a full rollback, which is invaluable when you detect an anomaly at 15% traffic and need time to investigate.
Rollback is not a fallback plan. It is a first-class deployment feature. Every model promotion should have a tested rollback path defined before the deployment begins.
How does continuous monitoring and retraining sustain model performance?
Production AI failures arise from lifecycle deficiencies rather than launch errors. A model that passes every offline evaluation can still degrade silently in production as the real world drifts away from the training distribution. This is the most common failure mode in deployed ML systems, and it is entirely preventable with the right monitoring setup.
Monitoring model health requires tracking data and prediction drift, not just system metrics like CPU and memory. Traditional infrastructure monitoring tells you the server is healthy. ML-specific monitoring tells you whether the model is still making good predictions.
The key monitoring signals to track in production:
- Data drift — The statistical distribution of input features shifts away from the training distribution. This often happens when upstream data pipelines change or user behavior evolves.
- Prediction drift — The model's output distribution changes without a corresponding change in inputs, which can indicate a model that has become miscalibrated.
- Ground truth feedback — Actual outcomes (labels) collected after prediction allow you to compute real-world accuracy, precision, and recall over time.
- Feature pipeline integrity — Missing values, schema changes, or upstream failures in the feature pipeline corrupt inputs before they reach the model.
- Data lineage validation — Confirming that the features served in production match the feature definitions used during training prevents silent training-serving skew.
Retraining triggers should be automated and threshold-based. When drift metrics cross a defined boundary, the pipeline fires a new training run using the most recent data window. Manual retraining schedules are a liability because they assume drift follows a calendar, which it does not.
The fastest ML lifecycle teams reduce friction between stages through automation rather than model complexity. A team that can retrain, validate, and redeploy in hours has a structural advantage over a team with a more sophisticated model that takes weeks to update.
Key takeaways
Effective ML lifecycle management requires continuous automation, governance by default, and progressive deployment to prevent silent model degradation and maintain production reliability.
| Point | Details |
|---|---|
| Lifecycle is a loop, not a line | Every production signal feeds back into development, making iteration speed a core operational metric. |
| Model registry is your audit trail | Link every model version to its training code, dataset, and environment to satisfy EU AI Act and SOC 2 requirements. |
| Progressive deployment reduces risk | Champion/challenger testing and canary releases make production failures recoverable before they affect all users. |
| Monitor ML health, not just system health | Track data drift, prediction drift, and ground truth feedback, not only CPU and memory metrics. |
| Automate retraining triggers | Threshold-based drift detection fires retraining automatically, removing the lag of manual monitoring schedules. |
Where most teams get the ML lifecycle wrong
After working with ML systems across a range of production environments, the pattern I see most often is not a failure of modeling skill. It is a failure of pipeline discipline. Teams spend months tuning a gradient boosting model or fine-tuning a transformer, then deploy it into a fragile data pipeline with no drift monitoring and no rollback plan. The model degrades within weeks. Nobody notices until a business stakeholder flags anomalous outputs.
The uncomfortable truth about understanding the ml lifecycle is that reliable data ingestion and feature pipeline construction matter more than model architecture for most production systems. A well-monitored linear model on a clean, versioned feature pipeline will outperform a complex neural network on a brittle, undocumented one. Every time.
Governance is the other area where I see teams create unnecessary friction. They treat compliance as a final review gate, which means it becomes a bottleneck. The better approach is governance embedded directly into pipelines, where approval workflows and audit logging run automatically on every stage transition. You get the same compliance coverage with a fraction of the delay.
The teams I have seen move fastest are not the ones with the most sophisticated models. They are the ones who have reduced the time from a detected drift signal to a validated, redeployed model. That cycle time is the real measure of ML lifecycle maturity. If your team cannot retrain and redeploy within a defined SLA when drift is detected, you do not have a lifecycle. You have a series of disconnected experiments.
— Kevin
How Mlflow supports your ML lifecycle from experiment to production

Mlflow is built around the full machine learning lifecycle, from experiment tracking and feature logging through model registry, deployment, and production observability. The Mlflow model registry gives your team a single source of truth for every model version, with built-in staging workflows, rollback support, and lineage linking that satisfies enterprise audit requirements. For teams running GenAI and LLM workloads, Mlflow's AI observability platform provides deep tracing and automated evaluation so you can monitor model health at the prediction level, not just the infrastructure level. Explore the full platform at mlflow.org and see how it fits your lifecycle.
FAQ
What is ML lifecycle management?
ML lifecycle management is the practice of overseeing every stage of a machine learning model's existence, from problem scoping and data preparation through training, deployment, monitoring, and retraining. It treats the process as a continuous loop rather than a one-time build.
How many stages are in the machine learning lifecycle?
The ML lifecycle contains 8–10 stages grouped into development, staging, and production phases. The exact count varies by organization, but all frameworks include problem scoping, training, validation, deployment, monitoring, and retraining.
What is a model registry and why does it matter?
A model registry is a centralized store that links each model version to its training code, dataset lineage, and environment configuration. It is the primary tool for satisfying auditability requirements under frameworks like the EU AI Act and SOC 2.
What is the difference between data drift and prediction drift?
Data drift occurs when input feature distributions shift away from the training distribution. Prediction drift occurs when the model's output distribution changes, which may signal miscalibration even when inputs appear stable.
How do you know when to retrain a model?
Retraining should trigger automatically when drift metrics cross a defined threshold or when ground truth feedback shows accuracy falling below an acceptable baseline. Manual retraining schedules are unreliable because model degradation does not follow a fixed calendar.