What Is Tool Use in AI Agents: A Technical Guide

Most AI agents people build today are severely limited, not by the model's reasoning quality, but by the absence of a well-designed tool layer. Understanding what is tool use in AI agents is the difference between shipping a capable production system and deploying an expensive chatbot. Tool use is the mechanism that transforms a language model from a static knowledge retriever into a system that can query live APIs, execute code, read files, and trigger workflows. This guide covers the architecture, optimization strategies, and real-world implications of tool use, specifically for researchers and technologists building or evaluating advanced AI systems.
Table of Contents
- Key Takeaways
- What is tool use in AI agents: core concepts
- Technical architecture for reliable tool use
- Optimization: reducing latency and token consumption
- Practical applications and implications
- My take on the tool layer problem
- Build production-ready agents with MLflow
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Tool use extends agent capabilities | AI agents rely on external tools to perform actions beyond their training data, including API calls, code execution, and file operations. |
| Tool definitions determine reliability | Clear input/output schemas and precise descriptions are what separate reliable tool calls from hallucinated ones. |
| Redundancy reduction is measurable | Optimized tool use frameworks have cut redundant tool calls from 98% to just 2%, with direct gains in accuracy and speed. |
| Long-running workflows need state management | Production agents require durable checkpoints and event-driven resumption, not conversation replay. |
| Observability is not optional | Tracing tool interactions is the only way to catch hallucinated parameters and debug multi-step agent failures. |
What is tool use in AI agents: core concepts
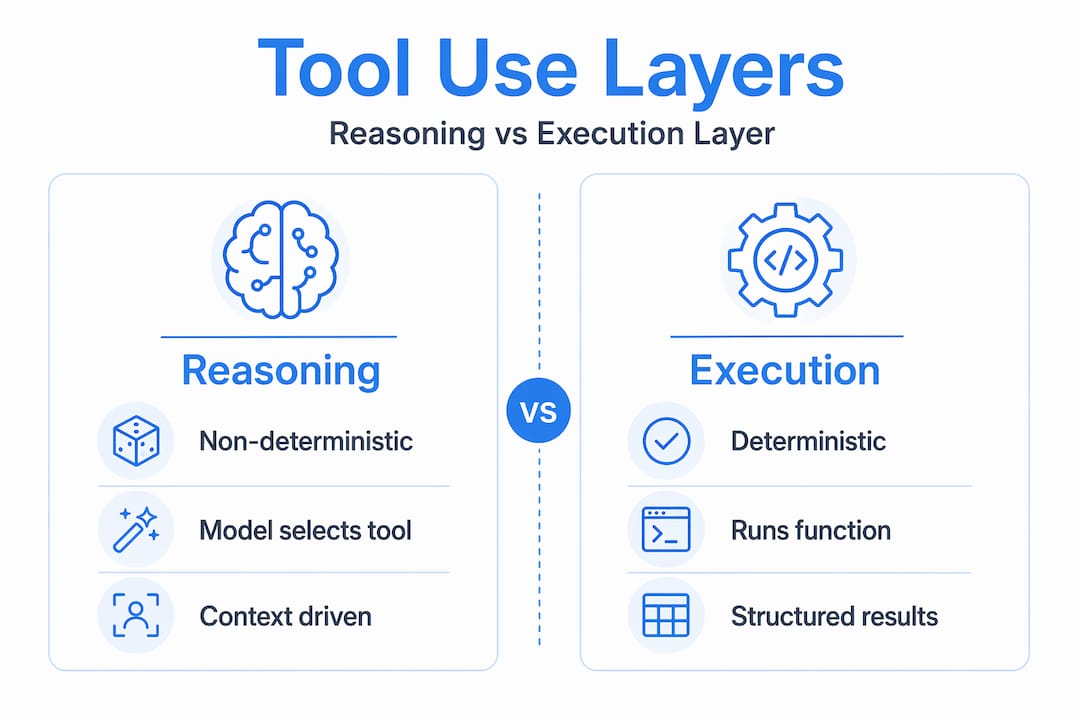
At its core, tool use in AI agents is the ability of a language model to request the execution of external functions and incorporate those results into its continued reasoning. The model itself does not execute the tool. The execution environment validates and runs the structured call the model emits, then returns the output for the next reasoning step. This separation between reasoning and execution is intentional. It keeps the model in the role of planner and the runtime in the role of executor, which is a critical boundary for safety and control.
The categories of tools available to agents span a wide range:
- Function calls: Locally defined Python or JavaScript functions that perform discrete computations, format data, or apply business logic.
- API calls: HTTP requests to external services, covering everything from weather data to CRM records to payment systems.
- Web search: Live retrieval of information that falls outside the model's training cutoff.
- Code execution: Sandboxed interpreters that let the agent generate and run code, then observe the output.
- File operations: Reading, writing, and parsing structured or unstructured documents.
- Sub-agent delegation: Handing off subtasks to specialized agents with their own tool sets.
The tool calling loop follows a consistent pattern. The model receives a user request, reasons over the available tools, emits a structured tool call request with a tool name and input parameters, the execution layer runs the call, and the result is fed back into the model's context for the next step. This loop can repeat multiple times before the agent returns a final response. Agentic AI represents a shift from simple input-output interaction to autonomous action sequences that unfold across multiple steps and tools.
The key conceptual distinction worth internalizing: the model is a non-deterministic reasoner, and the tool execution layer is deterministic. The model decides what to call and why. The runtime decides how to call it and enforces constraints.
Pro Tip: When designing your initial tool set, ask yourself whether each tool represents a single, unambiguous capability. If you find yourself writing a tool description that requires the word "or," you probably have two tools conflated into one.
Technical architecture for reliable tool use
Building tool use that actually works in production requires treating your tool definitions as a formal contract between the model and the execution environment. Underdefined tools produce underdefined behavior. Redefining a tool's description with explicit input/output schemas and usage guidance is often all it takes to move from broken to reliable agent behavior.
A well-structured tool definition includes:
- Name: A clear, unambiguous identifier that reflects exactly what the tool does. Avoid generic names like "process_data`.
- Description: One to three sentences that tell the model when to use this tool, not just what it does. Include usage constraints explicitly.
- Input schema: Typed parameters with descriptions and any allowed value ranges, formats, or enumerations.
- Output schema: Document what the return value looks like, especially error states. A model that has never seen your error format will not handle it gracefully.
- Usage examples (optional but high-value): A single example in the tool description dramatically improves call accuracy for complex parameters.
The architecture also needs to handle execution failures. Unhandled errors returned as raw stack traces create confusion at the model layer. Typed error responses with explanatory messages allow the model to reason about what went wrong and retry or escalate appropriately.
| Execution pattern | Latency | Risk | Best for |
|---|---|---|---|
| Sequential calls | Higher | Lower | Dependent steps, safety-critical workflows |
| Parallel calls | Lower | Higher | Independent operations, performance-critical tasks |
| Conditional branching | Variable | Medium | Dynamic workflows with optional steps |

Parallel tool calls reduce latency but introduce resolution complexity when outputs conflict or one call fails mid-execution. Sequential calls add latency but are far easier to trace and debug. For most production systems, the right answer is sequential by default with targeted parallelism introduced after profiling.
Tool usage logging is the non-negotiable foundation of any observable agent. Without full traces of which tools were called, with what parameters, and what they returned, debugging multi-step failures is nearly impossible. Tool call hallucinations, where the model calls a tool with syntactically valid but semantically wrong parameters, are one of the most common failure modes. Detailed event tracing during testing is how you catch these early before they surface in production.
Pro Tip: Build a circuit breaker into your tool execution layer that triggers after three consecutive failed calls to the same tool. This prevents runaway agent loops from consuming tokens and degrading user experience during partial outages.
Optimization: reducing latency and token consumption
Tool usage in AI without optimization is expensive. Every unnecessary tool call adds latency, consumes tokens, and degrades planning stability. This is not a minor inefficiency at scale; it is a deployment blocker.
The research here is striking. Alibaba's HDPO framework reduced redundant tool calls from 98% to just 2%, achieving 100% task completion while consuming far fewer tokens. The gain came not from a better model but from smarter tool orchestration and context management.
| Optimization technique | Mechanism | Measured impact |
|---|---|---|
| HDPO framework (Alibaba) | Redundancy detection and suppression | Redundant calls reduced from 98% to 2% |
| GA agent tool minimization | Atomic, irreducible tool set | Token consumption reduced by nearly 90% |
| Context truncation | Remove resolved steps from active context | Sustained performance over long horizons |
| Meta-memory compression | Summarize prior tool results in context | Preserves task state without token overflow |
Limiting the toolset to atomic, irreducible abilities is the core principle behind the GA agent framework's 90% reduction in token consumption. When tools overlap in scope, the model must spend extra reasoning steps disambiguating which tool fits the current step. Smaller, crisper tool sets produce more stable planning.
Context management compounds this. In long-running workflows, the growing history of tool calls and results quickly fills the context window, degrading performance and increasing cost. Effective strategies include truncating resolved intermediate steps, compressing past tool outputs into concise summaries, and writing explicit task state to external memory that the model can query on demand rather than carrying inline.
Pro Tip: Audit your production traces for repeated identical tool calls within a single agent run. If the same tool is being called more than twice with the same parameters, your agent is likely stuck in a reasoning loop caused by ambiguous task state, not tool failure.
Practical applications and implications
Understanding AI tool use is abstract until you see what it enables in practice. Here is where AI agent capabilities become genuinely transformative for enterprise and research contexts:
- Live data queries: Agents with API tools can pull current stock prices, sensor readings, or database records into their reasoning context, making decisions on information that is minutes old rather than months old.
- Automated multi-step workflows: A research agent can search the web, summarize findings, write a structured report to a file, and send it via email, all within a single agent run with no human intervention between steps.
- Long-running workflows with pause and resume: Google's approach uses persistent checkpoints and webhook-triggered wake-ups to let agents pause and resume over days or weeks. This matters for approval workflows, async data collection, and processes that depend on external events.
- Human-in-the-loop gates: Production agents that handle consequential actions, like sending emails or executing financial transactions, should route specific tool calls through explicit approval steps. This is not a limitation; it is a design pattern that makes agents deployable in regulated environments.
- Multi-agent delegation: Complex tasks are often best handled by a coordinator agent that delegates to specialized sub-agents, each with a focused tool set. This mirrors how engineering teams work and prevents individual agents from accumulating bloated tool catalogs.
Autonomous collaboration between agents is what MIT Sloan and Deloitte identify as the defining property of agentic AI. Tool use is the mechanism that makes that collaboration executable. Managing long-running AI agent workflows requires explicit durable state machines with atomic checkpoint writing and event-driven resumption, not conversation replay.
For enterprise integration, the implication is clear: the reliability and scalability of an AI agent is determined as much by tool design and orchestration architecture as by the underlying model. Teams that invest in well-defined tool contracts, observability infrastructure, and state management will consistently outperform teams that focus only on prompt engineering.
My take on the tool layer problem
I've spent a lot of time looking at where production AI agent deployments fail, and the pattern is consistent. Teams underestimate the tool layer. They spend weeks selecting the right model, tuning prompts, and evaluating output quality, then define their tools in an afternoon and wonder why the agent behaves unpredictably in production.
In my experience, the tool definition quality is the single biggest predictor of agent reliability. A mediocre model with excellent tool contracts and full observability will outperform a top-tier model with poorly documented tools and no tracing. I've seen this play out repeatedly. The model is doing its best with the information it has. When a tool description is ambiguous, the model makes a reasonable guess. That guess is wrong just often enough to cause real damage at scale.
What I find most encouraging is the optimization research coming out of production teams. The move from 98% redundant calls to 2% is not a small win. It's evidence that tool-layer engineering is a first-class discipline, not an afterthought. The teams building the most capable agents right now are the ones treating tool design with the same rigor they apply to model selection.
My advice: audit your tool descriptions before you audit your prompts. If your agent is failing, the answer is usually there.
— Kevin
Build production-ready agents with MLflow

The concepts in this article, from precise tool contracts to observability and multi-agent orchestration, require a platform that treats agent engineering as a discipline rather than a side feature. MLflow's AI agent platform provides production-grade tracing of tool calls and agent reasoning, automated evaluation using LLM-as-a-Judge frameworks, and a centralized AI Gateway for secure tool and prompt governance. You get deep visibility into exactly which tools were called, what parameters were passed, and how results shaped subsequent reasoning steps.
MLflow also supports prompt optimization for agentic workflows, helping teams reduce token consumption and improve tool selection accuracy across complex multi-step runs. If you are moving an agent from prototype to production, the open-source MLflow platform gives you the evaluation and serving infrastructure to do it without losing transparency.
FAQ
What is tool use in AI agents?
Tool use in AI agents is the mechanism by which a language model requests the execution of external functions, such as API calls, code execution, or database queries, and incorporates the results into its ongoing reasoning. The model emits structured tool call requests; the execution environment runs them and returns outputs.
How do AI agents decide which tool to call?
The model selects tools based on the tool descriptions provided in its system context. Clear, specific descriptions with defined input schemas lead to accurate tool selection. Ambiguous or overlapping descriptions cause the model to guess, which produces unreliable behavior.
Why do redundant tool calls happen?
Redundant tool calls typically occur when the agent's task state is ambiguous or when prior results are not clearly summarized in the context. Research shows optimized frameworks can cut redundant calls from 98% to 2% through better context management and tool orchestration.
What makes a tool definition reliable?
A reliable tool definition includes an unambiguous name, a description that specifies when to use it, typed input and output schemas, and documented error states. Redefining a tool's description with explicit usage guidance is often the fastest path to fixing broken tool call behavior.
How do long-running agents manage tool state?
Long-running agents require durable state machines with atomic checkpoint writing and event-driven resumption. Relying on conversation replay to reconstruct state is brittle and expensive. Production systems should persist task state externally and use webhook-triggered wake-ups to resume after pauses.