What Is AI Application Testing for QA Engineers

Knowing what is AI application testing means understanding that you are not dealing with conventional pass/fail QA. Unlike deterministic software, AI systems produce probabilistic outputs that shift based on context, training data, and model version. A feature that works perfectly today may degrade silently tomorrow. AI testing evaluates quality, risk, and real-world behavior continuously across the development lifecycle, not just during a pre-release sprint. This article breaks down the core dimensions of AI testing, the critical difference between model and agent evaluation, how security fits into your QA strategy, and practical methodologies you can apply right now.
Table of Contents
- Key takeaways
- What AI application testing actually covers
- Model evaluation vs. agent evaluation
- Balancing AI quality assurance with security testing
- Practical methodology for testing AI applications
- My take on what most teams get wrong
- How MLflow supports AI application testing end to end
- FAQ
Key takeaways
| Point | Details |
|---|---|
| AI testing is continuous | Evaluation must span the full lifecycle, not just pre-release gates or one-time checks. |
| Agents need trajectory testing | Task Success Rate and Tool Call Accuracy reveal failures that final-answer scoring misses entirely. |
| QA and security are both required | Functional quality checks and adversarial security testing address different failure modes in AI systems. |
| Behavior beats correctness | AI software validation focuses on consistency, fairness, and behavioral reliability, not just right answers. |
| Automation needs human judgment | Tone, helpfulness, and context appropriateness require LLM-based or human evaluation alongside automated checks. |
What AI application testing actually covers
The most common misconception in this field is treating AI application testing as traditional software testing with a few extra steps. It is not. Classical QA checks whether code executes the correct logic given specific inputs. AI testing asks whether a system behaves reliably, fairly, and safely across a distribution of inputs it has never seen before. That distinction shapes everything from how you write test cases to how you interpret results.
AI application testing covers a wide set of dimensions that go well beyond functional correctness. Here is what a complete AI testing program needs to address:
- Functional testing: Verifies that the AI system produces outputs consistent with its intended purpose. For an LLM-based customer service bot, this means checking whether responses are factually accurate, on-topic, and coherent across diverse prompts.
- Performance testing: Measures latency, throughput, and resource consumption under load. A model that scores well on accuracy benchmarks but takes eight seconds to respond is not production-ready.
- Bias and fairness testing: Checks whether the system produces equitable outputs across demographic groups, languages, or input styles. This is not optional in regulated industries.
- Robustness testing: Evaluates how the system handles noisy, malformed, or out-of-distribution inputs without catastrophic failure or hallucination.
- Regression testing: Verifies that a new model version, prompt update, or data change has not degraded previously acceptable behavior. This is far more complex for AI than for traditional software because the failure modes are probabilistic.
- Security testing: Probes for adversarial vulnerabilities such as prompt injection and jailbreaks, which are covered in depth later.
- Compliance testing: Confirms that the system meets regulatory requirements, content policies, and organizational governance standards.
The key shift is moving from evaluating correctness to evaluating quality, risk, and behavior. A model can return a technically correct answer while still failing on tone, introducing bias, or exposing sensitive information. Your test suite needs to catch all of it.
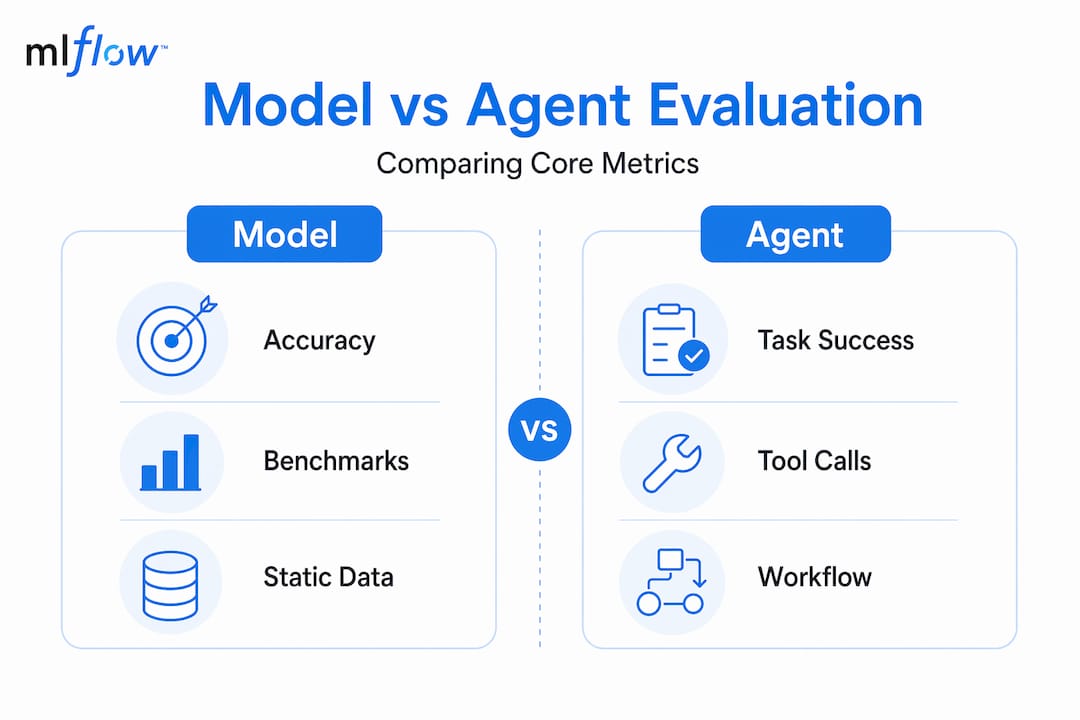
Model evaluation vs. agent evaluation
This distinction matters more than most teams realize, and collapsing the two leads to significant blind spots in your testing strategy.
Static model evaluation uses benchmarks like MMLU, TruthfulQA, or your own curated prompt sets to assess a foundation model's capabilities. These benchmarks are useful for comparing base models or measuring improvements from fine-tuning. However, model benchmarks assess base capabilities, not real-world dynamic performance. Once you wrap a model in an agent with tools, memory, and external API calls, benchmark scores become largely irrelevant to the quality of the deployed system.
Agent evaluation is fundamentally different. It measures end-to-end workflow performance across multi-step tasks where the agent must plan, call tools, interpret results, and reach a goal. The metrics that matter shift accordingly.
| Evaluation dimension | Static model | AI agent |
|---|---|---|
| Primary metric | Accuracy on benchmark | Task Success Rate |
| Tool use quality | Not applicable | Tool Call Accuracy |
| Reasoning efficiency | Token-level perplexity | Trajectory Efficiency |
| Failure detection | Wrong output | Wrong step in sequence |
| Test data type | Prompt/response pairs | Full interaction traces |
Agent evaluation focuses on end-to-end outcomes including Task Success Rate, Tool Call Accuracy, and Trajectory Efficiency rather than static benchmark scores alone. Consider a customer support agent that correctly tells the user their order is delayed. If the agent retrieved that information by calling the wrong API, ignored a rate limit, and made three redundant tool calls before arriving at the answer, it passed on the final-answer metric while failing on every meaningful quality dimension.

Trajectory-aware evaluation grades the full sequence of steps an agent takes, catching the "right answer, wrong tool" failure mode that end-only scoring misses entirely. This requires logging complete interaction traces, not just input/output pairs.
Pro Tip: Start logging full agent traces from day one of development, even during prototyping. Retrofitting trace instrumentation into a production agent is significantly more expensive than designing for observability from the start. MLflow's LLM tracing capabilities make this straightforward to implement early.
Balancing AI quality assurance with security testing
These are two complementary layers that address completely different failure modes. Treating them as interchangeable, or skipping one, leaves you with an AI application that is either unreliable in normal usage or vulnerable to deliberate exploitation.
AI quality assurance focuses on the system's usefulness and reliability under normal operating conditions. AI QA testing ensures accuracy and usefulness while AI security testing checks for manipulation risks, and both are required before you scale. Here is how to think about the security layer specifically:
- Prompt injection testing: Craft inputs that attempt to override system instructions or hijack agent behavior. A production LLM receiving user-submitted text must resist instructions embedded in that text that contradict the system prompt.
- Jailbreak testing: Attempt to bypass content policies using role-play, hypothetical framing, and indirect phrasing. Test systematically, not just with known examples.
- Data leakage testing: Verify that the model does not reveal training data, system prompts, internal documents, or other users' information when probed.
- Unauthorized action testing: For tool-using agents, verify that adversarial inputs cannot trigger unintended tool calls such as sending emails, modifying databases, or executing code outside the defined scope.
- Adversarial input testing: Inject noise, encoding tricks, and semantic perturbations to check whether the system's behavior degrades or becomes exploitable.
Security testing scenarios for AI include prompt injection, jailbreaks, and data leakage as distinct attack vectors that require dedicated test cases. These are not edge cases. In production, malicious users will probe your system within hours of deployment.
Pro Tip: Build a regression suite that combines functional QA cases and security test cases in the same automated pipeline. When you update a model or prompt, you want both quality and security coverage running simultaneously rather than in separate workflows.
Your QA and security tests should share infrastructure and run on every model update, prompt change, and dependency upgrade. Waiting until a security audit to check for prompt injection is the equivalent of testing for SQL injection after launch.
Practical methodology for testing AI applications
Understanding how to test AI applications requires more than a list of test types. You need a structured process that holds up across model updates, data drift, and shifting production conditions. Effective AI testing requires defining intended behavior, building diverse datasets, setting evaluation criteria, baseline testing, and continuous production monitoring.
Here is how to operationalize that in practice:
- Define intended behavior explicitly. Write a specification that describes what good outputs look like, what the system should refuse to do, what tone it should use, and how it should handle ambiguous inputs. Vague specs produce vague tests.
- Build a representative test dataset. Include normal cases, edge cases, adversarial inputs, and cases drawn from real production traffic. A dataset made entirely of easy prompts will not surface failures that matter.
- Set measurable evaluation criteria. Specify thresholds for accuracy, hallucination rate, toxicity scores, latency, and fairness metrics before you write a single test. Teams that define "good enough" after seeing results are rationalizing, not evaluating.
- Run baseline tests before deployment. Establish a performance baseline on your test dataset before any model goes to production. Every subsequent version gets compared against that baseline.
- Monitor continuously in production. AI testing must treat evaluation as a lifecycle loop with pre-launch baselines and continuous production monitoring because models and environments drift. Set up sampling pipelines that log real interactions and score them against your evaluation criteria on an ongoing basis.
- Document every test result. Version your test datasets alongside your model versions. When a regression appears, you need the history to determine whether the model changed or the data distribution shifted.
| Testing phase | Primary focus | Key output |
|---|---|---|
| Pre-development | Spec and criteria definition | Evaluation rubric |
| Pre-deployment | Baseline performance validation | Benchmark score |
| Post-deployment | Drift and regression monitoring | Alerting thresholds |
| Incident response | Root cause in trace data | Fixed test case |
Some quality attributes require human or LLM-based evaluation because automated metrics cannot reliably assess tone, contextual appropriateness, or nuanced helpfulness. Build that judgment into your pipeline through LLM-as-a-Judge scoring or structured human review, not as an afterthought.
My take on what most teams get wrong
I've seen teams migrate from traditional software QA into AI application testing and immediately try to apply the same deterministic pass/fail logic they've used for years. The instinct is understandable. It fails quickly.
The hardest mental shift is accepting that a correct output is not the same as a reliable system. I've watched agents produce accurate final answers while taking bizarre, wasteful, or potentially dangerous intermediate steps. Without full trajectory validation, those failures are invisible. You end up trusting an agent that is one prompt variation away from doing something you never intended.
What I've learned is that the teams who get AI testing right treat it as a design activity, not a verification activity. They instrument traces from day one, define behavioral specifications before writing code, and treat security test cases as first-class citizens alongside functional ones. The teams who struggle treat testing as something you bolt on before release.
The other thing most QA engineers underestimate is how much human judgment remains irreplaceable. Automated metrics catch volume. Human reviewers and LLM-as-a-Judge frameworks catch meaning. You need both, and neither substitutes for the other. The goal is a pipeline where automation handles scale and human judgment handles calibration.
— Kevin
How MLflow supports AI application testing end to end
Testing AI applications at production scale requires more than spreadsheets and ad hoc scripts. You need infrastructure that tracks experiments, stores traces, runs automated evaluations, and monitors production behavior in a single system.

MLflow is built specifically for this. The platform's agent and LLM evaluation capabilities let you define evaluation criteria, run LLM-as-a-Judge scoring, and compare model versions against your established baselines automatically. For security, MLflow's red teaming cookbook gives you structured guidance on adversarial testing integrated directly into your evaluation workflows. Production observability runs through MLflow's AI monitoring, which surfaces drift and regression signals before they become user-facing incidents. If you are building, testing, or deploying GenAI agents, the MLflow GenAI platform connects every phase of your testing lifecycle in one place.
FAQ
What is AI application testing?
AI application testing evaluates the quality, safety, fairness, and real-world behavior of AI-powered software across its full lifecycle, not just during pre-release validation. It includes functional, performance, bias, security, and regression testing specific to probabilistic AI systems.
How does agent evaluation differ from model evaluation?
Model evaluation uses static benchmarks to assess base capabilities, while agent evaluation measures end-to-end task performance using metrics like Task Success Rate, Tool Call Accuracy, and Trajectory Efficiency across dynamic multi-step workflows.
Why is trajectory testing important for AI agents?
Trajectory-aware evaluation grades each step an agent takes rather than only the final output, catching failures like incorrect tool calls or inefficient reasoning paths that final-answer scoring misses entirely.
What is the difference between AI QA and AI security testing?
AI QA testing verifies that a system is accurate, useful, and consistent under normal conditions. AI security testing specifically probes for adversarial vulnerabilities such as prompt injection, jailbreaks, and unauthorized tool execution that could be exploited by malicious users.
How do you select the right AI testing tools?
Choose AI testing tools that support trace logging, automated LLM-based evaluation, regression tracking, and production monitoring. The best tools integrate directly with your deployment pipeline so evaluation runs continuously rather than as a one-time check.