The Role of API Gateway AI Services in 2026

An AI gateway is defined as a centralized control plane that sits between your applications and LLM providers, enforcing governance, security, and operational controls across every AI request. The role of API gateway AI services goes far beyond simple request routing. Platforms like Databricks Unity AI Gateway, Tyk, and Envoy Gateway treat the gateway as the single authoritative layer for token management, cost attribution, PII masking, and multi-provider failover. For tech teams scaling AI from pilot to production, this layer is not optional. It is the infrastructure that makes enterprise AI deployable, auditable, and financially predictable.
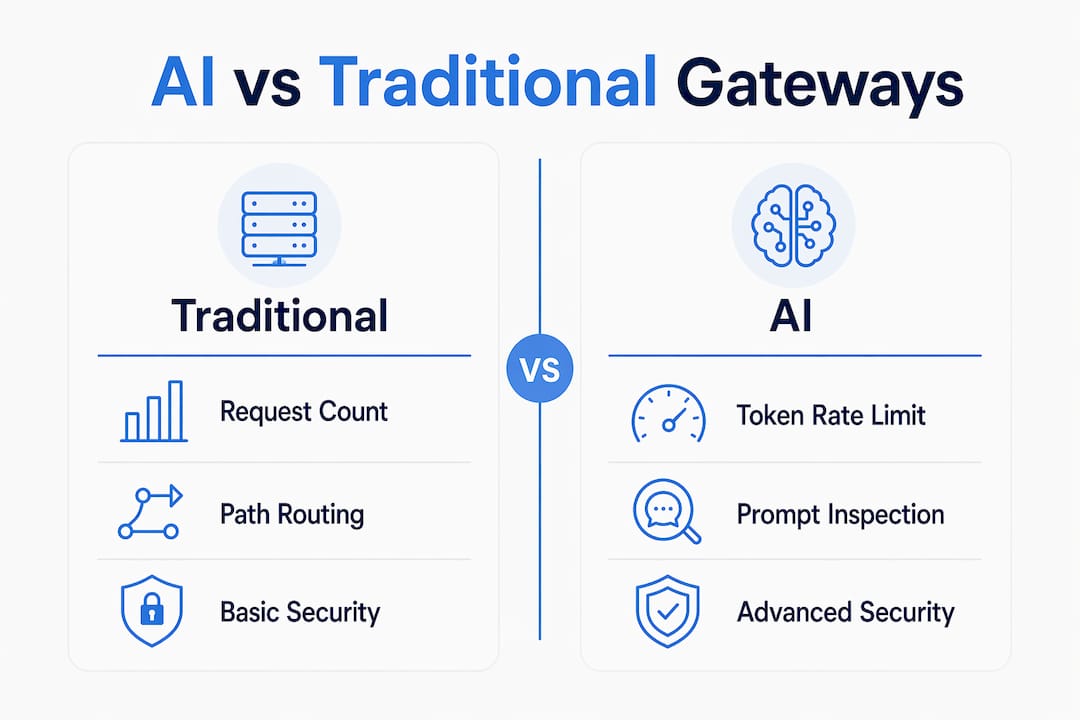
How do API gateway AI services differ from traditional API gateways?
Traditional API gateways were built for HTTP request routing, and they handle that job well. They count requests, enforce rate limits per endpoint, and validate credentials. But standard API gateways fail at LLM production workloads because they lack token-level management and the AI-specific observability required for multi-provider environments. A single GPT-4 prompt can consume thousands of tokens in one request. A request-count limit does nothing to prevent a runaway agent from spending $10,000 in an afternoon.
AI gateways enforce token-based rate limits per user or API key, which is the only control mechanism that maps to how LLMs actually consume compute and cost. This matters because token consumption is non-linear. A short prompt with a large context window can cost fifty times more than a simple completion request. HAProxy's AI gateway implementation highlights token-aware controls as the baseline requirement for any LLM workload, not an advanced feature.
Beyond rate limiting, AI gateways add capabilities that have no equivalent in traditional infrastructure. Prompt inspection, PII masking, content filtering, and routing decisions based on prompt complexity or provider latency are all AI-native functions. You can configure an AI gateway to route low-complexity prompts to a cheaper model and escalate complex reasoning tasks to a frontier model automatically. This kind of multi-model routing is impossible with a traditional API gateway that has no awareness of what is inside the request payload.

| Feature | Traditional API gateway | AI gateway |
|---|---|---|
| Rate limiting | Request count per minute | Token quota per user or API key |
| Routing logic | Path and method based | Prompt complexity, provider latency, model capability |
| Payload inspection | Headers and query params | Prompt content, PII detection, content filtering |
| Cost visibility | Request volume metrics | Token consumption per user, team, or endpoint |
| Failover | HTTP error codes | Model failure, latency threshold, provider switching |
Pro Tip: When evaluating AI gateways, test token quota enforcement under streaming workloads specifically. Traefik's documentation notes that consistent token limits under streaming require distributed state and shared counters across replicas, which many gateway implementations handle inconsistently.
What are the key security and governance features of API gateway AI services?
Security in AI environments introduces threat surfaces that did not exist in traditional API architectures. The gateway is the trust boundary, and every security policy must be enforced there before any downstream call reaches an LLM provider. Envoy Gateway's SecurityPolicy extension enforces mTLS, JWT validation, API key authentication, and OIDC integration at the gateway edge, with per-route customization for teams that need layered policies.
The core security and governance capabilities you should expect from a production AI gateway include:
- Authentication and authorization: mTLS, JWT, API key validation, and OIDC integration restrict access to authorized services and users only. Envoy Gateway's per-route SecurityPolicy allows platform teams to set a baseline and let individual teams customize within defined bounds.
- Role-based access control (RBAC): Centralized RBAC enforcement defines consistent policies for which teams can access which models and with what permissions. Without this, different teams create their own access patterns, and you lose the ability to audit or revoke access consistently.
- PII detection and masking: AI gateways inspect prompts for PII such as credit card numbers and Social Security Numbers, then scrub that data before forwarding requests to external providers. This is a compliance requirement for any organization operating under HIPAA, GDPR, or SOC 2 obligations.
- Content filtering and AI guardrails: Gateway-level content filters block harmful inputs and outputs before they reach users or downstream systems. This prevents prompt injection attacks and ensures AI-generated content meets organizational standards.
- Policy enforcement at the edge: Enforcing policies at the gateway rather than inside individual applications eliminates policy drift. When security rules live in application code, they diverge across teams. When they live at the gateway, every AI call is subject to the same controls.
Pro Tip: Treat agent communication security as a first-class concern from day one. Multi-agent architectures where sub-agents call other agents through the gateway create nested trust chains. Define RBAC policies that account for agent-to-agent calls, not just human-to-model calls.
How do API gateway AI services optimize performance and cost management?
Cost control is where AI gateways deliver some of their most concrete value. Without a gateway enforcing token quotas, a single misconfigured agent or a developer testing in production can generate costs that exceed a team's monthly budget in hours. The mechanisms AI gateways use to prevent this operate at four distinct levels.
- Token-aware quota enforcement: The gateway tracks token consumption across requests and responses, not just request counts. Quotas are set per user, per API key, or per team, and the gateway rejects or queues requests that would exceed the limit. This requires distributed state management, but it is the only approach that accurately reflects LLM cost structure.
- Cost attribution and FinOps visibility: Databricks Unity AI Gateway logs inference payloads and attributes token consumption to specific users, teams, and endpoints. This data feeds directly into cost reporting, so engineering and finance teams can see exactly where AI spend is going without manual instrumentation.
- Intelligent routing and load balancing: The gateway routes requests across providers based on latency, cost, and availability. A request that can be served by a cheaper model gets routed there automatically. Under high load, the gateway distributes traffic to prevent any single provider from becoming a bottleneck.
- Fallback and circuit-breaking: AI gateways implement fallback logic to detect model failure or latency spikes and reroute requests to alternative models. This protects production workloads from provider outages without requiring application-level retry logic in every service.
| Mechanism | What it controls | Business outcome |
|---|---|---|
| Token quota per API key | Per-request token consumption | Prevents cost overruns from runaway agents |
| Cost attribution logging | Spend per user, team, endpoint | Enables FinOps reporting and chargeback |
| Intelligent routing | Provider selection per request | Reduces cost by matching model to task complexity |
| Circuit-breaking | Provider failure and latency | Maintains uptime without application-level retries |
What practical benefits do API gateway AI services offer organizations?
The operational benefits of AI gateways compound as organizations scale from one AI use case to many. Managing a single OpenAI integration is straightforward. Managing simultaneous integrations with OpenAI, Anthropic, Google Vertex AI, and internal fine-tuned models across dozens of teams is a governance problem that only a centralized gateway can solve.
Structured inference logging in Unity Catalog turns raw AI gateway traces into queryable operational data. Security teams can audit every prompt and response. Cost teams can run queries against token consumption by department. Compliance teams can verify that PII masking fired on every external call. This level of AI observability is not achievable when each application manages its own LLM client.
The practical benefits organizations see in production include:
- Unified multi-vendor management: A single gateway configuration manages credentials, rate limits, and routing policies for OpenAI, Anthropic, Vertex AI, and internal models. Developers call one endpoint and the gateway handles provider selection.
- Shadow AI elimination: When all AI traffic flows through the gateway, unauthorized model usage becomes visible and blockable. Teams cannot bypass governance by calling provider APIs directly if network policies route all outbound AI traffic through the gateway.
- Developer self-service with guardrails: Teams can access new models and capabilities through the gateway without waiting for platform engineering to build new integrations. The gateway enforces organizational policies automatically, so speed and governance are not in conflict.
- Scalable AI adoption: As new models and providers emerge, the gateway abstracts provider-specific APIs behind a consistent interface. Applications do not need to be rewritten when you switch from one provider to another or add a new one.
Key takeaways
API gateway AI services are the operational control plane that makes enterprise AI deployable, auditable, and cost-predictable at scale.
| Point | Details |
|---|---|
| Token-based rate limiting | Quota enforcement must track tokens, not requests, to accurately reflect LLM cost and prevent overruns. |
| Security at the trust boundary | mTLS, JWT, RBAC, and PII masking must be enforced at the gateway before any downstream LLM call. |
| Cost attribution and observability | Inference logging tied to users and teams enables FinOps reporting and compliance auditing. |
| Intelligent routing and failover | Routing by model capability and automatic fallback protects production reliability without app-level retries. |
| Centralized multi-vendor governance | A single gateway managing OpenAI, Anthropic, and Vertex AI eliminates shadow AI and policy drift. |
Why the gateway layer deserves more strategic attention than it gets
Most teams I see treat the AI gateway as a late-stage infrastructure concern, something to bolt on after the first few models are in production. That sequencing creates real problems. By the time you add a gateway, you already have applications with hardcoded provider credentials, inconsistent retry logic, and no cost attribution. Retrofitting governance onto a system that was not designed for it is significantly harder than building it in from the start.
The deeper issue is that the gateway is not just an operational convenience. It is the trust boundary for your entire AI infrastructure. When a security incident occurs, and it will, the gateway is where you need to be able to answer: what was sent, by whom, to which model, and when. If that data does not exist because you were logging at the application layer inconsistently, your incident response is blind.
I have also seen teams underestimate the multi-agent dimension. When agents call other agents, the gateway needs to enforce policies on those internal calls too, not just on calls from human-facing applications. The RBAC model for a multi-agent system is fundamentally different from a model built around human users. Designing for that complexity early, rather than discovering it after deployment, is what separates teams that scale AI confidently from teams that are constantly firefighting.
The evolution toward AI orchestration frameworks and autonomous agents will make the gateway layer more critical, not less. As agents gain the ability to spawn sub-agents, call tools, and chain model calls, the gateway becomes the only place where you have consistent visibility and control across the entire execution graph.
— Kevin
Manage AI services at scale with MLflow AI Gateway

MLflow's AI Gateway platform gives engineering and platform teams a production-grade control plane for managing LLM and agent traffic across providers. It handles credential management, RBAC enforcement, token-aware rate limiting, and cost attribution out of the box. Inference traces are logged as structured data, so your security, compliance, and FinOps teams have the queryable audit trail they need. Failover and traffic-splitting configurations protect production workloads without requiring retry logic in every application. If you are building the infrastructure layer for enterprise AI, explore MLflow AI Gateway to see how governed, observable access to LLMs works in practice.
FAQ
What is the role of an API gateway in AI services?
An AI gateway acts as a centralized control plane between applications and LLM providers, enforcing token-based rate limits, security policies, cost attribution, and intelligent routing. Platforms like Tyk and Databricks Unity AI Gateway describe this as the layer that enables scaling from pilot projects to enterprise AI deployments.
How does an AI gateway differ from a traditional API gateway?
Traditional API gateways enforce request-count limits and path-based routing, which are insufficient for LLM workloads where a single prompt can consume thousands of tokens. AI gateways add token quota enforcement, prompt inspection, PII masking, and provider failover that traditional gateways cannot provide.
Why is token-based rate limiting important for AI gateways?
Token consumption is the actual cost driver in LLM workloads, not request volume. A gateway that limits requests but not tokens cannot prevent a single agent from generating disproportionate costs, which is why HAProxy and Traefik both treat token-aware controls as the baseline for AI gateway implementations.
How do AI gateways support security and compliance?
AI gateways enforce mTLS, JWT, API key validation, and OIDC at the edge, and they inspect prompts for PII before forwarding data to external providers. Envoy Gateway's SecurityPolicy extension and MLflow's RBAC enforcement demonstrate how centralized policy management eliminates the inconsistency that comes from application-level security implementations.
What observability capabilities do AI gateways provide?
AI gateways log inference payloads as structured data tied to specific users, teams, and endpoints. Databricks Unity AI Gateway converts these traces into queryable tables in Unity Catalog, enabling security audits, compliance verification, and FinOps cost reporting without additional instrumentation in individual applications.