Monitoring Agentic AI in Production: 2026 Guide

Monitoring agentic AI in production is the continuous observation of autonomous AI agents to confirm they perform as intended, stay within defined policies, and do not cause unintended side effects. Unlike traditional model monitoring, agentic AI oversight must track multi-step reasoning loops, tool calls, and state transitions across entire sessions. The stakes are high: an agent that silently fails or drifts outside its policy boundary can cause cascading errors before any alert fires. Mlflow addresses this directly with production-grade tracing, LLM-as-a-Judge evaluation, and a centralized AI Gateway built for exactly this kind of complex, multi-agent environment.
What metrics should you track when monitoring agentic AI in production?
Production AI observability separates two distinct metric categories: performance metrics and quality metrics. Real-time monitoring detects degradation before users feel it, especially in agentic retrieval-augmented workflows. Treating both categories equally is the foundation of any credible monitoring strategy.
Performance metrics cover the speed and throughput of your agent system:
- Latency (P50/P90/P99): Track all three percentiles. P99 latency reveals tail behavior that averages hide. An agent calling three external tools in sequence can spike P99 dramatically even when P50 looks healthy.
- Throughput: Measure requests per second at the session level, not just per LLM call. Agentic sessions are longer and more resource-intensive than single-turn completions.
- Token consumption per session: High token counts signal runaway reasoning loops or inefficient prompt construction.
Quality metrics require a different monitoring approach because they cannot be measured with simple thresholds:
- Hallucination frequency: Track how often agent outputs contain claims unsupported by retrieved context. LLM-as-a-Judge frameworks automate this at scale.
- Grounding and relevance accuracy: For retrieval-augmented agents, measure whether retrieved chunks actually support the final answer.
- Retrieval precision: Low precision means the agent is working with noisy context, which compounds downstream errors.
Cost and safety metrics are the third category most teams underweight:
- Turn budgets: Monitoring turn budgets limits iterations per session to prevent runaway costs and infinite loops. A common ceiling is 25 turns before triggering human intervention. High turn-budget hit rates signal model instability or ineffective prompts.
- Cost circuit breakers: Set session-level cost limits that halt execution and alert on-call engineers before a single runaway session drains your budget.
Pro Tip: Set separate alert thresholds for P99 latency and turn-budget hit rate. If both spike together, the root cause is almost always a prompt regression or a newly introduced tool with high failure rates.
Which architectural approaches ensure reliable agentic AI governance?
Governance embedded as a first-class operator in the decision pipeline provides formal guarantees that post hoc corrections cannot. Embedding governance as a deterministic projection operator gives you stable constraint enforcement, verifiable audit trails, and bounded decision drift. This is the CAIS (Corrigible AI System) framework approach, and it is the architecture production teams are moving toward in 2026.
The core principle is that governance must intercept every action before execution, not after. Runtime policy enforcement kernels perform deterministic policy checks at sub-millisecond latency using policy languages like OPA Rego or Cedar. They block goal hijacking, unauthorized tool calls, and out-of-scope actions without adding perceptible latency to the user experience.
Telemetry contracts are the second architectural pillar. These are external specifications that define exactly what state transitions, tool-call outcomes, and decision points your monitoring infrastructure must capture. Self-reporting logs by agents are insufficient for observability. When an agent fails, it often fails to log the failure accurately. External telemetry contracts capture tool-call results independent of the agent's internal reasoning, which prevents hidden failure modes from going undetected.

| Approach | Mechanism | Key benefit |
|---|---|---|
| Runtime policy kernel | OPA Rego or Cedar intercepts every action | Sub-millisecond deterministic enforcement |
| Governance as operator | Projection operator in decision pipeline | Formal constraint guarantees and audit trails |
| External telemetry contracts | State transitions captured outside agent | Eliminates self-reporting blind spots |
| Supervisory AI agents | Runtime artificial controllers monitor and intervene | Scalable oversight distinct from human-in-the-loop |
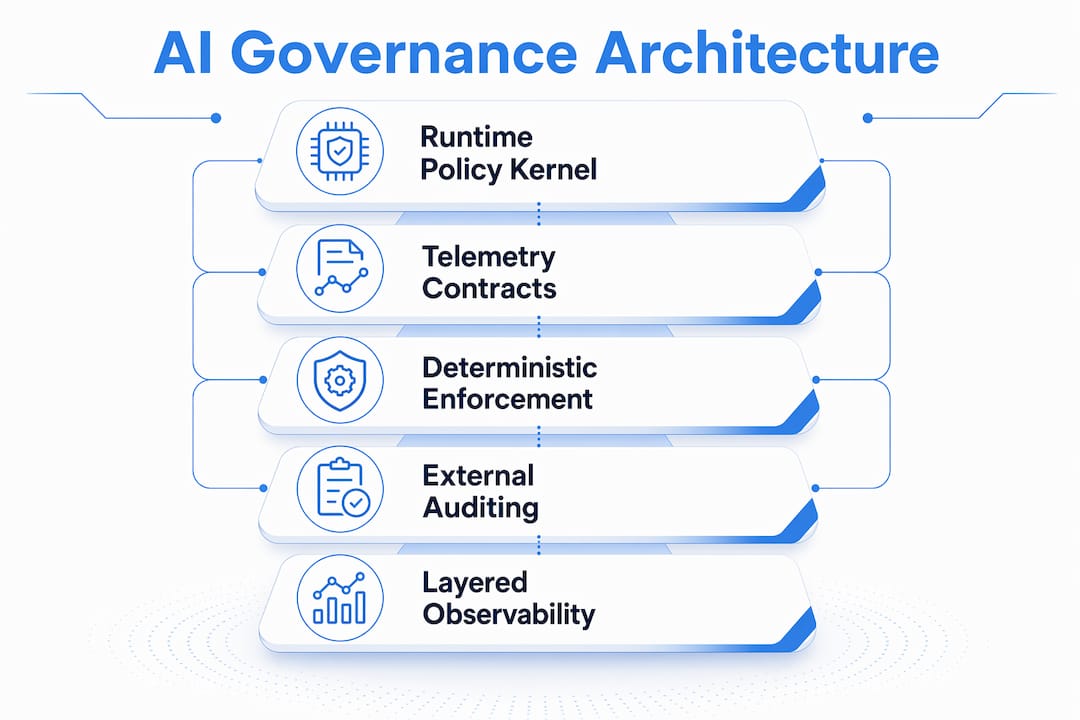
Pro Tip: Do not rely on prompt-level safety instructions as your primary governance layer. Deterministic policy kernels are not fooled by adversarial inputs the way prompt guards are. Use both, but treat the kernel as your enforcement layer and prompts as your guidance layer.
How do you implement observability for full agent loops?
Agent observability requires tracking entire agent loops, including planning, tool execution, observation, and decision cycles, not just individual LLM calls. Agent loop tracking is fundamentally different from monitoring a single model inference. A single user session can involve dozens of LLM calls, multiple tool invocations, and several replanning steps. You need visibility into all of them.
Here is a practical implementation sequence for production teams:
- Instrument at the loop level. Use distributed tracing tools like OpenTelemetry (OTel) and Jaeger to create spans that cover the entire agent session, not just individual model calls. Each span should capture the agent's current goal, the tool it called, the tool's response, and the agent's next decision.
- Track iteration counts per session. Log how many planning-execution cycles each session completes. Sudden increases in average iteration count indicate a prompt regression or a tool that is returning unexpected outputs.
- Monitor tool call frequency and failure rates. Break down tool calls by type. A search tool failing 30% of the time will not show up in overall latency metrics but will destroy answer quality.
- Capture session-level cost. Aggregate token consumption and API costs at the session level. This is the unit that matters for budget control, not the per-call level.
- Set boundary conditions. Define what "normal" looks like for iteration count, session cost, and tool call depth. Alert when any session exceeds two standard deviations from baseline.
Correlating model monitoring with system-level telemetry is what separates teams that can diagnose incidents quickly from teams that spend hours guessing. Integrated observability reduces guesswork during incident analysis and identifies root causes accurately. Without it, distinguishing a model failure from an infrastructure issue takes far too long.
Mlflow's AI observability platform provides deep tracing of agentic reasoning across multi-agent systems, giving your team the correlated view that makes incident analysis tractable.
What are the common pitfalls in agentic AI monitoring?
The most dangerous blind spot in production AI management is trusting agent self-reports. Agents that encounter errors often produce plausible-sounding outputs rather than explicit error messages. External telemetry contracts that capture state transitions independently of the agent's own logs are the only reliable defense.
Several other pitfalls consistently trip up production teams:
- Conflating model failure with infrastructure failure. A slow database response can cause an agent to retry excessively, which looks like model instability in the logs. Always correlate model telemetry with infrastructure metrics before drawing conclusions.
- Inadequate human oversight design. Meaningful human oversight requires designing systems that enforce evaluative agency, meaning humans can intervene and contest AI decisions with clear accountability mappings. Simple human-in-the-loop checkboxes do not meet this bar. You need layered explanations and contestability built into the workflow.
- Missing idempotency keys. Idempotency keys for every external action an agent takes are vital for auditability and preventing duplicate side effects on retries. This is especially critical in regulated domains where a double-executed payment or database write has real consequences.
"Designing for evaluative agency means giving human reviewers enough context to make a meaningful judgment, not just a binary approve or reject button." — Springer Nature, 2026
Pro Tip: Build a "layered explanation pack" for every agent decision that triggers a human review. Include the agent's goal at that step, the tool it called, the tool's raw output, and the agent's interpretation. Reviewers who see all four layers make better decisions and catch more errors.
Mlflow's structured evaluation framework helps teams embed this kind of contestability into their production workflows, connecting evaluation data directly to the decision pipeline.
Key Takeaways
Effective agentic AI oversight requires layered observability, deterministic governance, and external telemetry that operates independently of agent self-reporting.
| Point | Details |
|---|---|
| Separate metric categories | Track performance, quality, and cost metrics independently to catch different failure modes. |
| Enforce governance deterministically | Use runtime policy kernels like OPA Rego to intercept every action before execution. |
| Use external telemetry contracts | Capture state transitions outside the agent to eliminate self-reporting blind spots. |
| Monitor full agent loops | Track iteration counts, tool call rates, and session costs, not just individual LLM calls. |
| Design for evaluative agency | Give human reviewers layered context so they can meaningfully contest agent decisions. |
Why deterministic governance is the real shift in production AI
The conversation in AI monitoring has moved past "should we add guardrails" and into "how do we make governance structurally unavoidable." That shift matters more than any specific tool choice.
What I have seen consistently in large-scale AI operations is that teams underestimate how different agentic systems are from the model monitoring they already know. A single LLM call is a transaction. An agent session is a process. Monitoring a process requires tracking state over time, not just measuring outputs at a point in time. Teams that apply their existing model monitoring playbook to agents end up with dashboards that look fine while the system is quietly failing.
The move toward runtime deterministic governance, where policy kernels intercept every action before it executes, is the most important architectural trend I see in 2026. It is not glamorous. It does not show up in demos. But it is what separates AI systems that are genuinely trustworthy from ones that are merely well-intentioned. Combining that with system-level telemetry correlation gives SRE teams the ability to shift from reactive firefighting to proactive operations. That is the goal worth building toward.
— Kevin
Mlflow for production-grade agentic AI monitoring
Teams that have worked through the practices above need a platform that ties them together without requiring custom glue code for every integration.

Mlflow provides production-grade AI observability with deep tracing of agentic reasoning, automated LLM-as-a-Judge evaluation, and a centralized AI Gateway for cross-provider governance. Its tracing layer captures full agent loops, including tool calls, state transitions, and replanning steps, giving your team the correlated view that makes incident analysis fast. For teams building on top of complex orchestration frameworks, Mlflow's agent and LLM engineering platform standardizes evaluation and serving so you can move from prototype to production with confidence. Explore the prompt engineering cookbook to see how prompt-level improvements connect directly to monitoring outcomes.
FAQ
What is agentic AI monitoring?
Agentic AI monitoring is the continuous observation of autonomous AI agents to confirm they operate within defined policies, produce reliable outputs, and do not cause unintended side effects across multi-step sessions.
How is agent observability different from standard LLM monitoring?
Standard LLM monitoring tracks individual model calls. Agent observability must track entire loops including planning, tool execution, observation, and replanning cycles, along with session-level costs and iteration counts.
What is a turn budget in agentic AI?
A turn budget is a hard limit on the number of planning-execution cycles an agent can complete in a single session. A common limit is 25 turns, after which the system triggers human intervention to prevent runaway costs or infinite loops.
Why are external telemetry contracts important?
Agents that encounter errors often fail to log those errors accurately. External telemetry contracts capture state transitions and tool-call outcomes independently of the agent's own logs, eliminating the blind spots that self-reporting creates.
How does runtime policy enforcement differ from prompt safety?
Runtime policy kernels like OPA Rego or Cedar intercept every agent action before execution using deterministic rules. Prompt safety layers are advisory and can be bypassed by adversarial inputs. Policy kernels provide formal enforcement guarantees that prompt guards cannot.
Recommended
- Building Production-Ready AI Agents in 2026 | MLflow
- AI observability for production: Seeing Inside Your Multi-Agent System with MLflow | MLflow
- AI Agent Tool Use Best Practices for Practitioners | MLflow
- Structuring AI Evaluation and Observability with MLflow: From Development to Production | MLflow