Top 6 Arize Alternatives Software 2026

Maintaining real-time visibility into large language model performance and failures often means stitching together fragmented logs and incomplete metrics across tools. Many observability solutions either force teams into closed SaaS platforms with limited self-hosting or lack features like prompt tracking, traceability, and deep audit controls needed for enterprise LLM deployments. This comparison breaks down open source and enterprise-ready observability platforms so you can match the right solution to your team's workflow, governance, and scale requirements.
Table of Contents
- MLflow
- Langfuse
- Evidently AI
- UpTrain
- Latitude
- Lunary
- Comparing AI Observability Tools for Large Language Model Operations
MLflow
At a Glance
The vendor reports over 26K GitHub stars for MLflow, a visible signal of community activity and contributor momentum. MLflow is open source and framework-agnostic while offering experiment tracking, model registry, observability, and agent-focused features for teams moving beyond prototypes.
Core Features
- Experiment tracking that records runs, parameters, and artifacts across languages and frameworks.
- Model registry and deployment with versioning, stage transitions, and deployment hooks.
- Observability and tracing for AI applications plus score monitoring and safety metrics.
- Prompt registry and optimization tailored to LLMs and agent workflows.
- Agent deployment and a unified API gateway for LLM providers.
Key Differentiator
MLflow’s distinguishing trait is its open source, extensible architecture combined with built-in observability and deployment primitives for both ML and LLM workflows. That mix lets teams trace agentic reasoning, manage prompts centrally, and connect the same lifecycle tooling to research experiments and production agents.
Pros
- Open source and free. The source code and extension points let engineering teams customize behavior and embed MLflow into CI pipelines.
- Framework-agnostic support across PyTorch, TensorFlow, XGBoost, and other tools reduces lock-in when models and runtimes change.
- Strong lifecycle coverage from experiment tracking to deployment. Teams keep the same audit trail from prototype to production.
- Observability features surface metrics and traces that help debug agent reasoning and model drift sooner in the release cycle.
- Active community resources and docs accelerate onboarding. The community figure above is useful when searching for plugins and integrations.
Cons
- Setup complexity can be steep for small teams. Integrating storage, tracing backends, and access controls requires infrastructure work and operations time.
Notable Integrations
- OpenTelemetry for traces and metrics.
- LangChain for LLM orchestration and prompt pipelines.
- Native connectors for PyTorch, TensorFlow, and XGBoost model artifacts.
- Kafka and cloud storage services for ingestion and artifact persistence.
Who It's For
AI engineers and data scientists who need a single, open-source control plane for experiments, model lifecycle, and agent observability. Best for teams that can dedicate engineering resources to configure scalable storage, tracing, and access controls.
Unique Value Proposition
A centralized AI Gateway for secure prompt management and cross-provider governance. That capability reduces ad hoc prompt sprawl, enforces prompt versioning, and shortens the path from LLM experiments to governed agent deployments across providers.
Real World Use Case
A large enterprise data science team uses MLflow to track experiments across languages, evaluate model candidates with automated metrics, trace agent decision steps in production, and manage prompt versions through a central gateway. The same registry and traces feed deployment automation across multiple clouds.
Website: https://mlflow.org
Langfuse
At a Glance
Langfuse reports more than 2,300 companies using the platform and processing billions of observations monthly. The project is open-source and offers self-hosting, which gives engineering teams control over data and deployment choices. That mix appeals to teams that need visibility without vendor lock-in.
Core Features
- Tracing and graphing of LLM calls and agent behavior so you can follow an inference from prompt to final output.
- Prompt management with versioning and deployment controls for experiment reproducibility and rollback.
- Evaluation and scoring pipelines that automate model output checks and surface regression signals.
- Metrics and analytics dashboards for latency, cost, and quality monitoring across models and experiments.
- Native SDKs for Python and JavaScript and support for OpenTelemetry to instrument other languages.
Key Differentiator
Langfuse combines open-source licensing with built-in tracing that natively accepts OpenTelemetry data. That lets teams instrument agents and model calls the same way they do application telemetry and keeps traces portable across stacks. The emphasis is on developer control and data portability rather than a closed hosted telemetry silo.
Pros
- Easy developer onboarding. The SDKs and examples get you from zero to visible traces quickly so debugging starts the same day you integrate.
- Detailed tracing plus latency and cost analytics help you pinpoint expensive prompts and slow model hops without guessing.
- Prompt versioning and deployment controls reduce drift between experiments and production, making rollbacks straightforward.
- Open-source and self-host options let security teams keep logs and artifacts in their own environment, useful for strict data policies.
- Works with common LLM frameworks and gateways, so you can add Langfuse to an existing pipeline without rewriting core logic.
Cons
- Vendor and third-party writeups list no broad negatives, which may reflect limited public criticism rather than perfection.
- Self-hosting requires ops effort. Teams should expect a learning curve and resource planning for storage and processing of large trace volumes.
- Some enterprise capabilities such as custom SLAs and prioritized support sit behind higher paid tiers, which may matter for mission critical deployments.
Notable Integrations
- OpenTelemetry SDKs for Python and JavaScript for language-agnostic tracing.
- Frameworks and libraries including LangChain, Vercel SDK, and Pydantic AI for faster instrumenting of model pipelines.
- Model providers like OpenAI, Anthropic, and Google Gemini for direct provider-level telemetry correlation.
- Gateways such as Helicone, Vercel, and OpenRouter plus no-code builders and analytics tools for ingestion and visualization.
Who It's For
Developers and AI teams building and deploying LLM applications who want full visibility into prompts, responses, and agent workflows. Solo engineers can use the free tier to prototype. Security-conscious enterprises can self-host to keep data on prem.
Real World Use Case
According to the vendor, a Fortune 50 tech company uses Langfuse to trace and debug generative features in production. Teams there used the traces to identify frequent hallucination triggers and to reduce mean time to resolution for agent failures.
Pricing
Free for hobby use. Paid tiers start at $29/month for Core, $199/month for Pro, and $2499/month for Enterprise. Enterprise plans include additional support and deployment options tailored to large organizations.
Website: https://langfuse.com
Evidently AI
At a Glance
The vendor advertises 7,500+ GitHub stars, 40M+ downloads, and 3,000+ community members — a strong open-source signal for teams that prize visibility and community-driven tooling. Evidently AI focuses on evaluation and observability for LLMs and complex AI workflows.
It targets testing, drift detection, safety checks, and adversarial scenarios rather than model training or data labeling. That focus shapes where you will deploy it in your stack.
Core Features
- Automated evaluation of AI output accuracy, safety, and factuality with predefined and custom metrics.
- Synthetic data generation to exercise edge cases and adversarial conditions for robustness testing.
- Continuous monitoring for data drift and model performance with alerts and historical comparisons.
- Test multi-step AI workflows and tool integrations end to end.
- Built-in and customizable metrics for safety, factuality, bias, and robustness.
Key Differentiator
Evidently AI's marketing materials highlight an open-source foundation with more than 100 built-in metrics and an active community. That architecture makes the tool highly transparent and extendable for teams that want to instrument models with domain-specific checks.
Because the metric suite is modular, you can add company policies or regulatory checks without rebuilding core pipelines.
Pros
- Open-source base and an active community make customization visible and auditable. You can fork checks, add metrics, and trace contributions.
- Helps detect hallucinations, bias, data leaks, and other failure modes early so you can block bad model updates before release.
- Supports end-to-end testing and diagnostics across multi-step pipelines, which makes it useful for agentic chains and tool-augmented LLMs.
- Private cloud deployment and role-based access are available for enterprise environments that require isolation and compliance.
- The adoption signals above make it easier to find community examples, shared metrics, and troubleshooting patterns when you run into issues.
Cons
- Deep customization often requires engineering effort. Teams without SRE or ML infra capacity will find initial setup and metric tuning time consuming.
- The product concentrates on evaluation and monitoring. It does not provide model training, versioned dataset storage, or full MLOps pipelines on its own.
- Some users report a learning curve for integration into complex, multi-team environments and for translating safety policies into executable checks.
When It May Not Fit
If your primary need is model development, experiment tracking, or dataset labeling you will be duplicating functionality elsewhere. Evidently AI focuses on post-training evaluation and runtime observability.
If your team lacks bandwidth for infra work, the setup and customization burden will slow time to value. Expect engineer time for integrations and custom metric development.
Who It's For
AI teams, ML engineers, and data scientists building LLM-driven products that require rigorous evaluation, safety gating, and continuous monitoring at scale. Large organizations that need private deployment and RBAC will get the most from Evidently AI.
Real World Use Case
A large enterprise running an LLM chat system wires Evidently into their inference stack to log outputs, run factuality and bias checks, and monitor distributional shifts after each deployment. When drift or hallucination rates rise, the alerts trigger rollbacks and targeted retraining.
That workflow turns safety policies into repeatable, auditable checks across updates and tool integrations.
Pricing
Not applicable — Evidently AI is open-source with enterprise options available on request. Commercial offerings typically cover support, private deployment assistance, and SLAs rather than software licensing.
Website: https://evidentlyai.com
UpTrain
At a Glance
UpTrain's marketing materials state it is backed by YCombinator and positions itself as an open-source full-stack LLMops platform for evaluation, experimentation, and regression testing. The vendor also advertises more than 20 predefined metrics for diverse evaluation needs.
Core Features
UpTrain centralizes evaluation, experimentation, regression testing, and team collaboration for LLM workflows. It provides automated regression testing with prompt and code versioning to catch regressions before deployment. The platform includes root cause analysis, enriched datasets, and hooks for production log ingestion. Custom metrics and dataset enrichment let engineers reproduce and test edge cases from real traffic.
Key Differentiator
The core differentiator is an open-source architecture combined with a design for enterprise scale. That combo lets teams modify evaluation pipelines, host on-premises for governance, and integrate rigorous testing into CI. For groups that need both auditability and scale, the open codebase is a practical advantage.
Pros
- Open-source core promotes transparency and customization. Teams can inspect scoring pipelines, swap components, or extend metrics without vendor lock-in.
- Scales to large datasets reliably. The vendor describes high reliability for heavy workloads, which matters when you run daily regression sweeps across many models.
- Strong tooling for systematic experimentation. Versioned prompts and evaluation suites let you compare model changes with repeatable runs.
- Cost-efficient scoring techniques are part of the evaluation stack, helping reduce evaluation spend when running large-scale tests.
- Support for self-hosting and data governance aligns with security and compliance needs for regulated deployments.
Cons
- Expect a learning curve. The platform exposes advanced LLMops controls that require engineering time to use effectively.
- Pricing details are sparse in public materials, implying custom or enterprise-focused contracts rather than simple per-seat tiers.
- Setup complexity can be high for small teams or projects with minimal LLM footprint; the platform may feel heavy for single-model experiments.
When It May Not Fit
If you are an individual researcher or a two-person proof-of-concept team, UpTrain's enterprise orientation and setup overhead may slow you down. If you need a plug-and-play hosted SaaS with simple per-seat pricing, this product's self-host and customization emphasis could be misaligned.
Who It's For
AI research teams, data science groups, and enterprise AI teams maintaining multiple LLMs who require repeatable evaluation, governance controls, and CI-integrated regression testing. Ideal when you need audit trails, custom metrics, and the option to self-host.
Real World Use Case
A company running several customer-facing LLMs wires production logs into UpTrain, builds enriched test datasets from edge-case traffic, and automates nightly regression tests after model updates. Engineers triage failures using root cause analysis and roll back changes faster because tests reproduce the error cases.
Pricing
Public materials list pricing as not applicable and suggest custom or enterprise engagement. That implies conversations with sales for hosted options or support contracts for self-hosted deployments rather than a published per-seat plan.
Website: https://uptrain.ai
Latitude
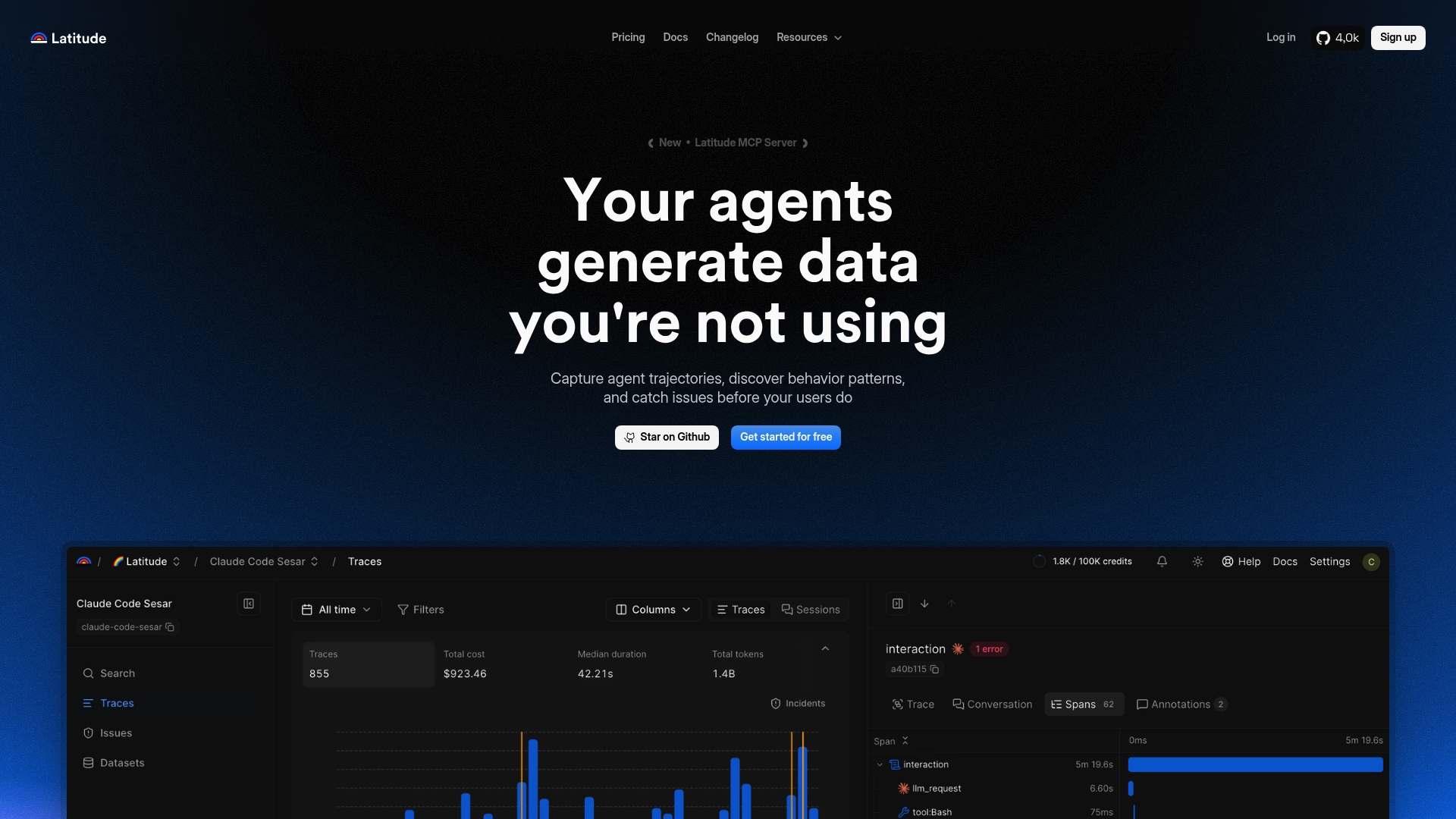
At a Glance
Open source with self-hosting and a Pro tier at $99 per month, which gives you a clear pay-to-scale option without locking the code. The platform targets production LLM observability with traceability, automated failure grouping, and continuous evaluation workflows.
Core Features
- Full traceability of AI behavior in production for session-level auditing and event timelines.
- Semantic and exact search across traces so you can locate problematic conversations by meaning or token match.
- Automatic issue detection and alerting plus failure grouping and trend analysis to prioritize engineering work.
- Continuous evaluation pipelines that run tests against live traffic and provide feedback for prompt optimization.
Key Differentiator
The standout is its focus on production tracing tied to failure analysis rather than ad hoc logging. That design maps model decisions to conversation context and system signals, which speeds root-cause work and helps you reproduce hard-to-find regressions.
Pros
- Deep observability into model behavior and failures. You get session traces, metadata, and groupings that shorten the mean time to resolution.
- Open source with self-hosting options gives full control over data residency and customization for regulated environments.
- Automated detection and classification of failure modes reduce alert noise and highlight the most impactful incidents.
- Enables continuous evaluation and prompt optimization so you can iterate on prompts with measurable regressions and improvements.
Cons
- Third-party reviews indicate the initial setup can be complex for teams without platform engineering bandwidth. Expect a nontrivial integration effort.
- Some advanced features require technical expertise in observability tooling and LLM internals to get full value out of them.
- Enterprise capabilities are custom-priced, so total cost for large deployments depends on negotiated terms rather than published tiers.
When It May Not Fit
If your team lacks an engineer who can wire pipelines, instrument traces, and manage a self-hosted stack, Latitude will add operational overhead rather than reduce it. Small research teams that need low-effort hosted telemetry might prefer a managed alternative.
Notable Integrations
- OpenAI
- Google Cloud AI
- AWS SageMaker
- Anthropic
- Cohere
- Vertex AI
- Hugging Face
Who It's For
AI engineers, MLOps, and DevOps teams running LLMs or agent frameworks in production who need traceable conversations, automated failure grouping, and the option to self-host. Teams that require vendor neutrality and deep signal-level debugging will find it particularly relevant.
Real World Use Case
An engineering team monitors a customer support chatbot in real time, uses semantic search to find repeated failure patterns, and applies continuous evaluation tests to verify prompt fixes. The result is fewer repeated incidents and faster iteration on problematic intents.
Pricing
Free tier available. Pro plan at $99 per month for expanded features. Enterprise plans are custom-priced and negotiable based on scale and hosting preferences.
Website: https://latitude.so
Lunary
At a Glance
Self hostable deployments plus a free tier and paid plans starting at $20 per user/month make Lunary a strong pick for teams that need both on premises control and a cloud option. The vendor advertises compliance with SOC 2 and ISO 27001.
Lunary bundles live analytics, chat replays, and prompt management so production incidents are traceable to a single interaction quickly.
Core Features
- Chat replays and log archive that let you replay prompts and responses for debugging and postmortem analysis.
- Prompt templates, an experimentation playground for A/B tests, and feedback tracking for iterative improvement.
- Custom dashboards for usage, cost, and performance, plus topic classification and agent tracing for root cause work.
- PII masking and fine grained access control to support stricter data governance and audit requirements.
- SDKs and one line integration with OpenAI, Anthropic, Llama, and other LLM providers, plus destinations like MySQL and BigQuery.
Key Differentiator
The product’s real advantage is offering a true self hostable option combined with enterprise tooling for monitoring and security. That combo lets security teams retain data ownership while engineering teams keep modern observability: replayable sessions, anomaly alerts, and integrated prompt versioning in a single stack.
Pros
-
Strong observability: chat replays and real time error tracing cut mean time to resolution on model failures.
-
Security first: the platform supports PII masking and fine grained controls that help meet internal governance requirements.
-
Broad integrations: built in connectors for LLM providers and databases reduce glue code between model and analytics layers.
-
Collaboration features: dashboards, human review workflows, and prompt templates let product, ML, and ops teams work from the same artifacts.
-
Open source options and local deployment paths give teams control over infrastructure and cost profiles.
Cons
-
Pricing can be high for larger teams; operational costs rise once you scale many seats or heavy log retention.
-
The platform’s breadth adds complexity; small projects or solo practitioners may be overburdened by configuration needs.
-
Public materials do not detail specific model level performance metrics, which makes vendor comparisons harder.
-
Self hostable deployments require engineering effort and ongoing maintenance from your infra team.
When It May Not Fit
If you need a tiny, low touch prototype, Lunary’s setup and governance surface area will slow you down. Small startups with one or two engineers and tight budgets will find the pricing and configuration overhead disproportionate.
Also avoid Lunary if you need turnkey model benchmarking dashboards out of the box; the product expects technical staff to shape metrics and alerts.
Notable Integrations
- OpenAI, Anthropic, Llama, Azure OpenAI
- DeepSeek, PowerBI, Tableau, MySQL
These integrations cover model endpoints and analytics destinations, letting you stream logs to warehouses and visualize metrics in BI tools.
Who It's For
AI teams inside enterprises, ML engineers, and data scientists who need production grade monitoring, replayable audits, and strict data governance. Good for organizations that can dedicate infra resources to a self hostable deployment and want to own their data.
Real World Use Case
A large corporation runs customer service chatbots through Lunary to capture every interaction, replay incidents, and route flagged conversations to human reviewers. Security logs and PII masking keep sensitive fields out of analytics while teams tune prompts based on replayed failure cases.
Pricing
There is a free tier at $0 and paid plans starting at $20 per user/month, with custom enterprise options for self hostable and white label deployments. Enterprise quotes vary by retention and deployment model.
Website: https://lunary.ai
Comparing AI Observability Tools for Large Language Model Operations
Selecting the right observability tool for managing LLM and AI workflows involves assessing capabilities, compatibility, and operational considerations. Below is a comparison of leading platforms, highlighting how their features align with specific requirements.
Deployment and Customization Flexibility
MLflow.org stands out with its open-source model and extensive integration capabilities, empowering teams to adapt workflows to unique operational needs. Its strengths in lifecycle management and compatibility with frameworks such as PyTorch or TensorFlow enhance flexibility. While Langfuse also provides an open-source option and supports straightforward tracing setup, UpTrain excels with enterprise-oriented customization and scalability, though it may require deeper engineering expertise during setup.
Operational Efficiency and Managerial Features
Langfuse facilitates efficient debugging with intuitive tracing SDKs and detailed latency analytics, crucial for smaller teams needing fast onboarding. Contrastingly, Evidently AI focuses on safety and adversarial robustness evaluations. Its specialized metrics and signal monitoring address advanced operational constraints, making it superb for AI safety-critical applications, albeit requiring substantial upfront customization.
Best Fit Scenarios
-
MLflow.org: Preferred by organizations requiring a unified control plane for AI experiment tracking, lifecycle management, and integrated observability. Teams capable of tailoring infrastructure will maximize its benefits.
-
Langfuse: Well-suited for teams initiating observability in LLM workflows due to its ease of integration and concise cost-analytical tracer capabilities.
-
Evidently AI: Ideal for enterprises focused on post-training evaluations and safety compliance policies, seeking thorough drift monitoring and adversarial case testing.
Our Pick
MLflow.org is especially advantageous when AI projects demand interconnected experimentation and production deployment workflows within a flexible, open-source ecosystem. However, teams prioritizing simplicity and out-of-the-box tracing for prompt feedback might explore Langfuse as an alternative for initial implementations.
Large Language Model Observability Platforms Comparison
Selecting the right large language model observability platform involves evaluating tools based on key differentiators like lifecycle management, traceability, and deployment flexibility.
| Product | Core Feature | Key Differentiator | Best For | Pricing | Notable Limitation |
|---|---|---|---|---|---|
| MLflow | Experiment tracking and model registry | Open-source extensibility with observability features | AI engineers needing full lifecycle coverage | Not disclosed | Setup complexity for small teams |
| Langfuse | Detailed tracing across LLM pipelines | Supports OpenTelemetry for portable telemetry traces | Developers needing visibility in AI workflows | Starting $29/month | Self-hosting requires operations effort |
| Evidently AI | Accuracy and safety monitoring | Modular metric suite for customizable evaluations | ML engineers evaluating safety policies | Open-source | Requires engineering effort for setup |
| UpTrain | Regression testing and RLHF support | Root cause analysis for enriched dataset generation | Teams scaling reproducible evaluations | Not disclosed | Significant setup complexity for small teams |
| Latitude | Full production observability | Failure detection and classification in session traces | Teams needing fault analysis in LLM systems | Free, Pro $99/month | Requires engineering for advanced setup |
Take Control of Your GenAI and LLM Lifecycle with MLflow
Choosing the right platform for your AI model management can feel overwhelming, especially when looking at arize.com alternatives that promise observability but require complex setups or offer limited integration options. If you want a solution that bridges experiment tracking, production-grade observability, and centralized prompt governance, MLflow delivers an open-source, framework-agnostic platform built specifically to manage AI Agent lifecycles effectively.
With MLflow you get:
- Deep tracing of agent reasoning to identify issues early
- Automated evaluation using LLM-as-a-Judge frameworks
- A unified AI Gateway for secure prompt versioning across providers

Discover how MLflow can reduce guesswork and empower your AI teams at MLflow official site. Take charge of your GenAI pipelines and deploy robust, transparent agents today by exploring the comprehensive features designed to move you beyond prototypes to scalable production systems.
Frequently Asked Questions
How does MLflow handle experiment tracking for large language models?
MLflow provides experiment tracking that records runs, parameters, and artifacts across languages and frameworks. This feature ensures that teams maintain a comprehensive audit trail from prototype to production, facilitating better model comparison and performance evaluation. You should consider MLflow if you need consistent monitoring across different ML projects.
What is the difference between MLflow and Langfuse in terms of data tracing?
Langfuse offers detailed tracing of LLM calls and agent behavior, which helps teams follow an inference from prompt to final output effectively. In contrast, MLflow focuses on a broader range of lifecycle management, including model deployment and observability. Evaluate your specific needs for tracing versus comprehensive lifecycle management when choosing between the two.
Which platform provides better observability features for AI applications, MLflow or Evidently AI?
Evidently AI specializes in evaluation and monitoring, with a focus on drift detection and safety checks, making it particularly strong for scenarios needing rigorous analysis of AI behavior. Meanwhile, MLflow's observability features help debug agent reasoning and model drift sooner in the release cycle, offering a good balance for continuous monitoring. Choose depending on whether evaluation or immediate observability is your priority.
Can I use MLflow effectively if my team lacks extensive engineering resources?
While MLflow is open source and customizable, its setup complexity can be daunting for smaller teams without dedicated engineering resources. Given that integrating storage, tracing backends, and access controls requires substantial configuration, consider starting with MLflow if your team can allocate the necessary effort to configure the system.
What is the pricing structure for MLflow, and is it different from its competitors?
MLflow is open source and free to use, unlike some competitors like UpTrain and Langfuse, which offer tiered pricing models starting at $29/month and $29/month respectively. This makes MLflow a cost-effective option for teams that can manage their own infrastructure and do not require premium support options.