Serving
Flexible Model Deployment
Deploy your ML and DL models with confidence using MLflow's versatile serving options for real-time and batch inference
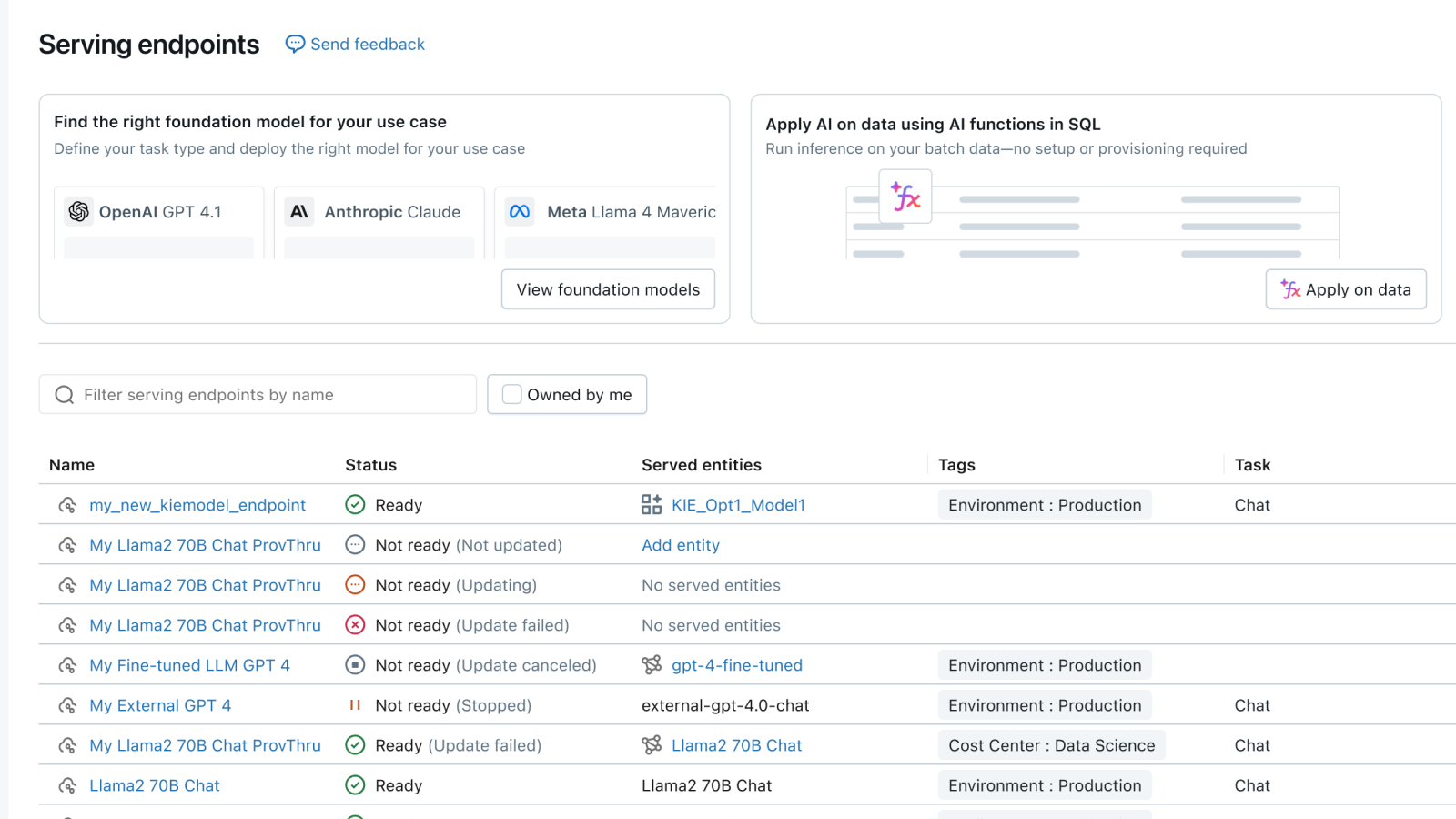
Scalable Real-Time Serving
MLflow provides a unified, scalable interface for deploying models as REST APIs that automatically adjust to meet demand fluctuations. With managed deployment on Databricks, your endpoints can intelligently scale up or down based on traffic patterns, optimizing both performance and infrastructure costs with no manual intervention required.
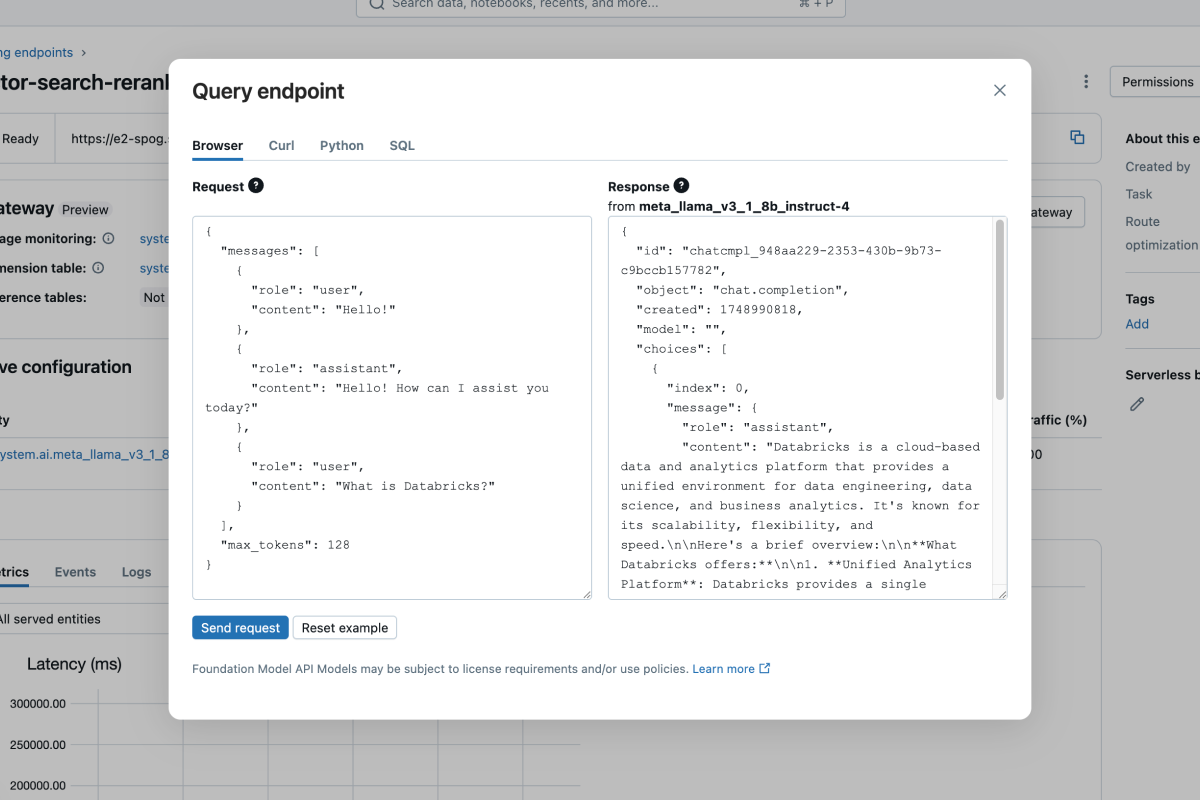
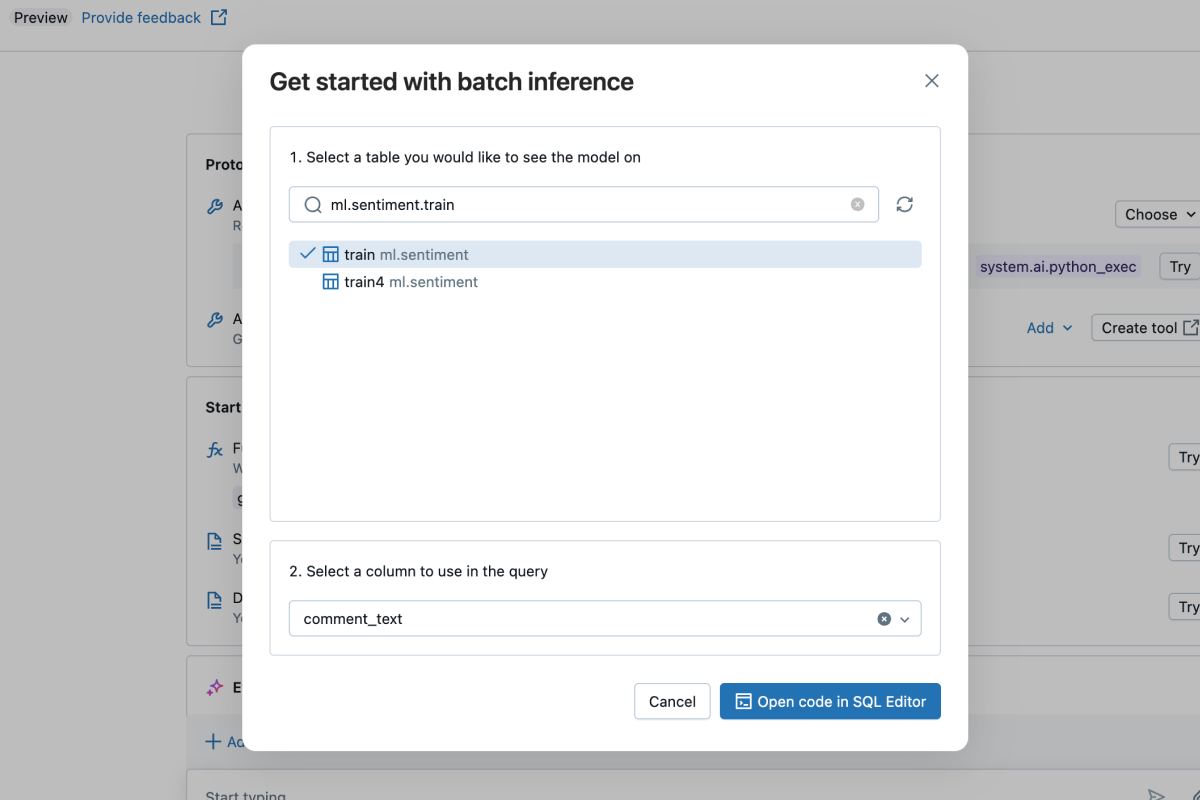
High-Performance Batch Inference
Deploy production models for batch inference directly on Apache Spark, enabling efficient processing of billions of predictions on massive datasets
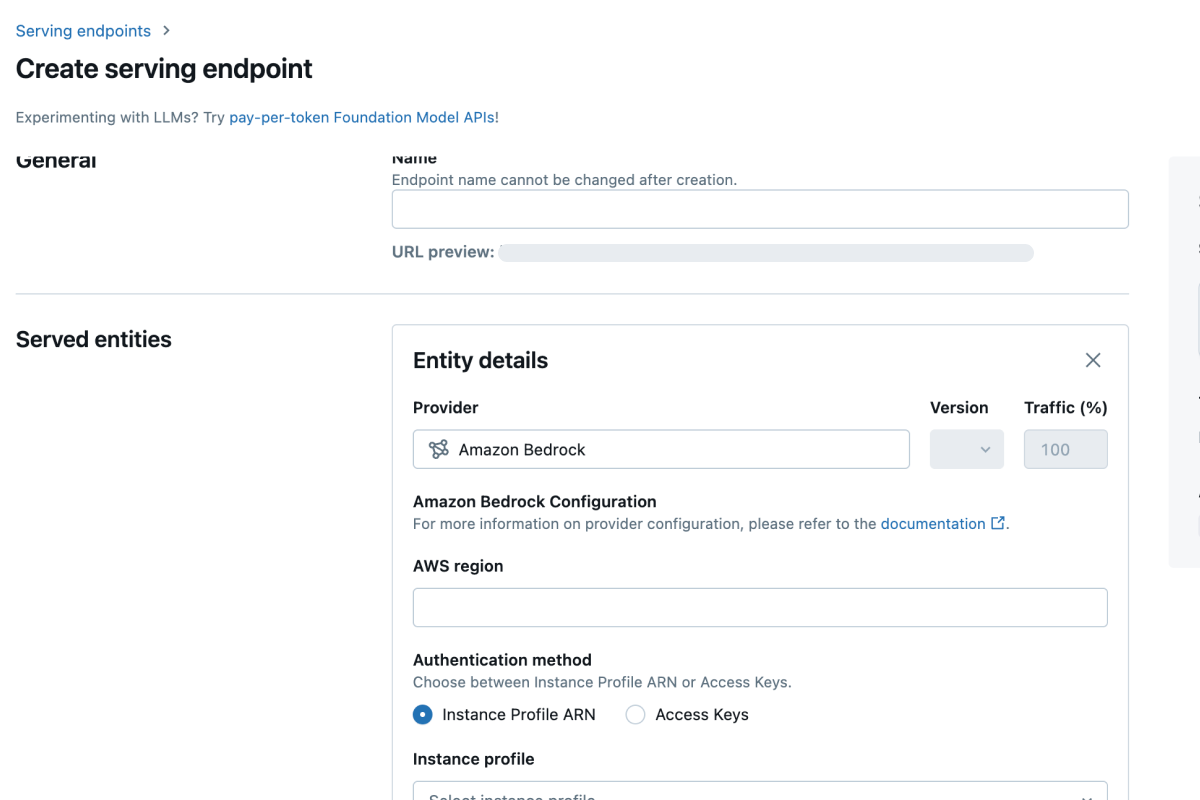
Comprehensive Deployment Options
Deploy models across multiple environments including Docker containers, cloud services like Databricks, Azure ML and AWS SageMaker, or Kubernetes clusters with consistent behavior.
Get started with MLflow
Choose from two options depending on your needs
GET INVOLVED
Connect with the open source community
Join millions of MLflow users