MLflow Transformers Flavor
Attention
The transformers flavor is in active development and is marked as Experimental. Public APIs may change and new features are
subject to be added as additional functionality is brought to the flavor.
Introduction
Transformers by 🤗 Hugging Face represents a cornerstone in the realm of machine learning, offering state-of-the-art capabilities for a multitude of frameworks including PyTorch, TensorFlow, and JAX. This library has become the de facto standard for natural language processing (NLP) and audio transcription processing. It also provides a compelling and advanced set of options for computer vision and multimodal AI tasks. Transformers achieves all of this by providing pre-trained models and accessible high-level APIs that are not only powerful but also versatile and easy to implement.
For instance, one of the cornerstones of the simplicity of the transformers library is the pipeline API, an encapsulation of the most common NLP tasks into a single API call. This API allows users to perform a variety of tasks based on the specified task without having to worry about the underlying model or the preprocessing steps.
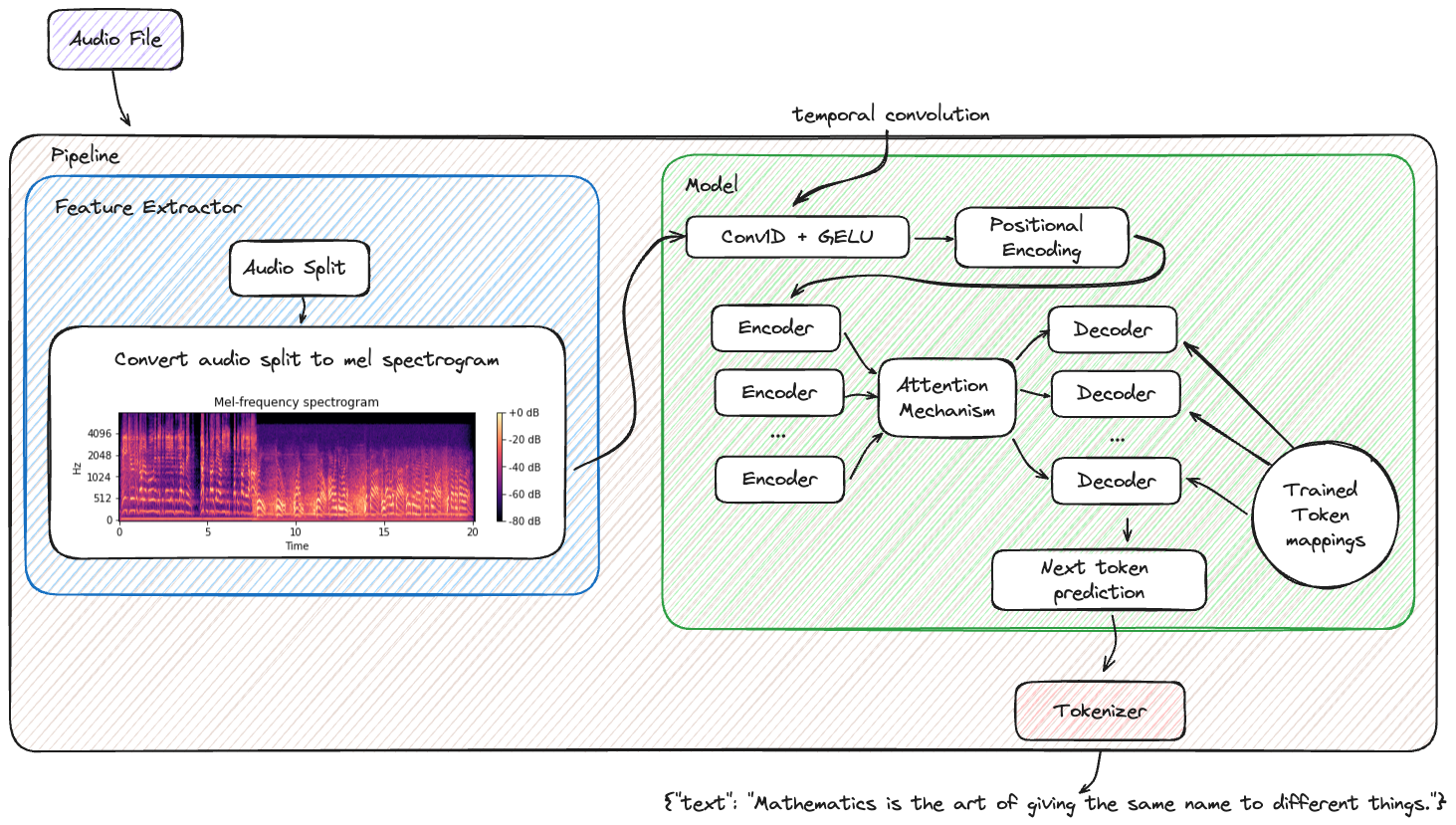
The integration of the Transformers library with MLflow enhances the management of machine learning workflows, from experiment tracking to model deployment. This combination offers a robust and efficient pathway for incorporating advanced NLP and AI capabilities into your applications.
Key Features of the Transformers Library:
Access to Pre-trained Models: A vast collection of pre-trained models for various tasks, minimizing training time and resources.
Task Versatility: Support for multiple modalities including text, image, and speech processing tasks.
Framework Interoperability: Compatibility with PyTorch, TensorFlow, JAX, ONNX, and TorchScript.
Community Support: An active community for collaboration and support, accessible via forums and the Hugging Face Hub.
MLflow’s Transformers Flavor:
MLflow supports the use of the Transformers package by providing:
Simplified Experiment Tracking: Efficient logging of parameters, metrics, and models during the fine-tuning process.
Effortless Model Deployment: Streamlined deployment to various production environments.
Comprehensive Model Support: Compatibility with a broad range of models from the Transformers library.
Enhanced Performance: Integration with libraries like Hugging Face Accelerate for improved model performance.
Fine-tuning of Foundational Models: Users can fine-tune transformers models on custom datasets while tracking metrics and parameters.
Experiment Tracking: Log experiments, including all relevant details and artifacts, for easy comparison and reproducibility.
Simplified Model Deployment: Deploy models with minimal configuration requirements.
Prompt Management: Save prompt templates with transformers pipelines to optimize inference with less boilerplate.
Example Use Case:
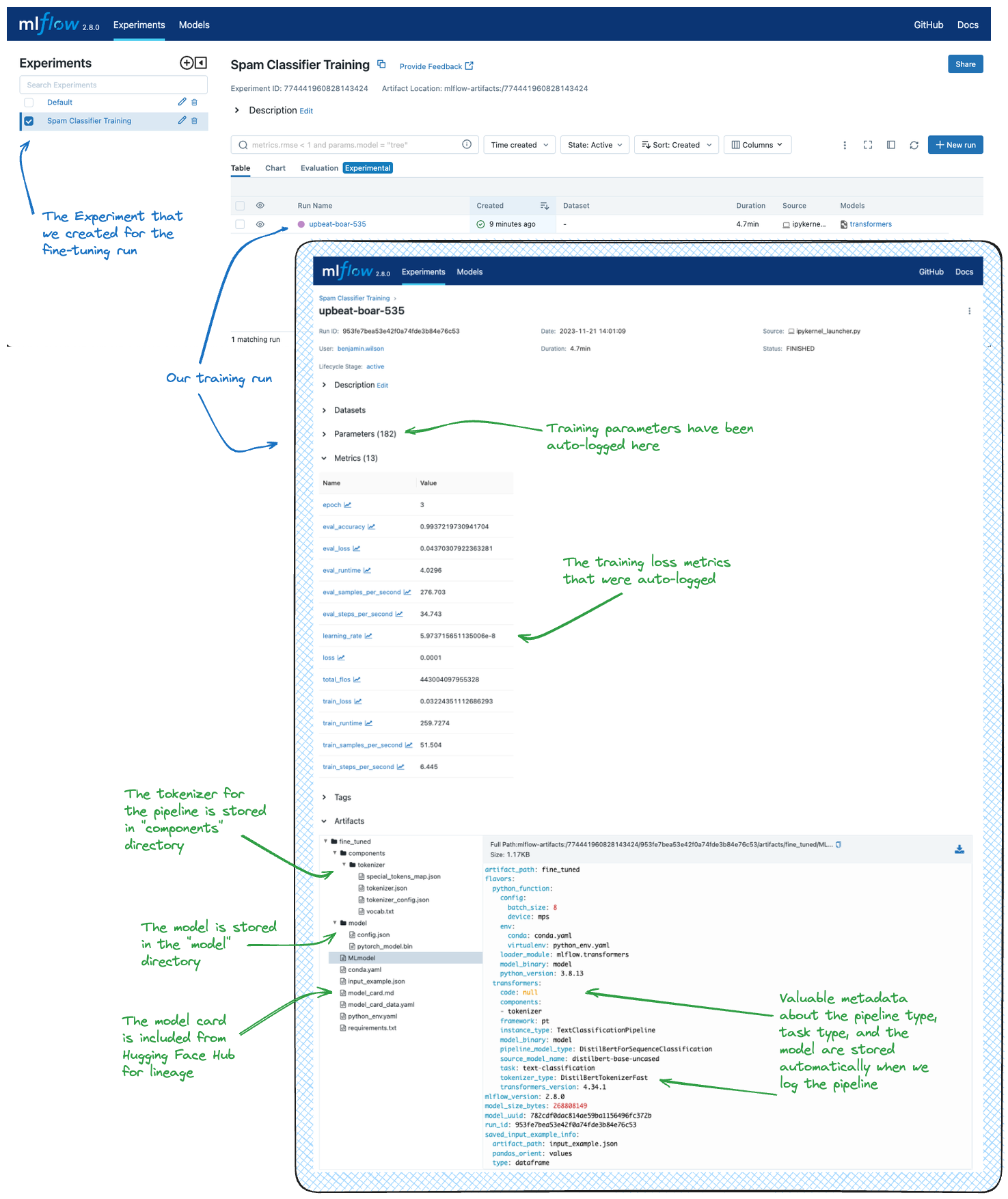
For an illustration of fine-tuning a model and logging the results with MLflow, refer to the fine-tuning tutorial. The tutorial demonstrates creating a spam classifier pipeline, and the image below shows the result of that tutorial within the MLflow UI.
Deployment Made Easy
Once a model is trained, it needs to be deployed for inference.
MLflow’s integration with Transformers simplifies this by providing functions such as mlflow.transformers.load_model() and
mlflow.pyfunc.load_model(), which allow for easy model serving.
As part of the feature support for enhanced inference with transformers, MLflow provides mechanisms to enable the use of inference
arguments that can reduce the computational overhead and lower the memory requirements
for deployment.
Getting Started with the MLflow Transformers Flavor - Tutorials and Guides
Below, you will find a number of guides that focus on different use cases (tasks) using transformers that leverage MLflow’s APIs for tracking and inference capabilities.
Introductory Quickstart to using Transformers with MLflow
If this is your first exposure to transformers or use transformers extensively but are new to MLflow, this is a great place to start.
Use Case Tutorials for Transformers with MLflow
Interested in learning about how to leverage transformers for tasks other than basic text generation? Want to learn more about the breadth of problems that you can solve with transformers and MLflow?
These more advanced tutorials are designed to showcase different applications of the transformers model architecture and how to leverage MLflow to track and deploy these models.
Download the Use Case Tutorial Notebooks to try them locally
To download the transformers tutorial notebooks to run in your environment, click the respective links below:
Download the Audio Transcription NotebookDownload the Translation Notebook
Download the Chat Conversational Notebook
Download the Fine Tuning Notebook
Download the Prompt Templating Notebook
Download the Custom PyFunc transformers Notebook
Options for Logging Transformers Models - Pipelines vs. Component logging
The transformers flavor has two different primary mechanisms for saving and loading models: pipelines and components.
Pipelines
Pipelines in the context of the Transformers library are high-level objects that combine pre-trained models and tokenizers (as well as other components, depending on the task type) to perform a specific task. They abstract away much of the preprocessing and postprocessing work involved in using the models.
For example, a text classification pipeline would handle the tokenization of text, passing the tokens through a model, and then interpreting the logits to produce a human-readable classification.
When logging a pipeline with MLflow, you’re essentially saving this high-level abstraction, which can be loaded and used directly for inference with minimal setup. This is ideal for end-to-end tasks where the preprocessing and postprocessing steps are standard for the task at hand.
Components
Components refer to the individual parts that can make up a pipeline, such as the model itself, the tokenizer, and any additional processors, extractors, or configuration needed for a specific task. Logging components with MLflow allows for more flexibility and customization. You can log individual components when your project needs to have more control over the preprocessing and postprocessing steps or when you need to access the individual components in a bespoke manner that diverges from how the pipeline abstraction would call them.
For example, you might log the components separately if you have a custom tokenizer or if you want to apply some special postprocessing to the model outputs. When loading the components, you can then reconstruct the pipeline with your custom components or use the components individually as needed.
Important Details to be aware of with the transformers flavor
When working with the transformers flavor in MLflow, there are several important considerations to keep in mind:
Experimental Status: The Transformers flavor in MLflow is marked as experimental, which means that APIs are subject to change, and new features may be added over time with potentially breaking changes.
PyFunc Limitations: Not all output from a Transformers pipeline may be captured when using the python_function flavor. For example, if additional references or scores are required from the output, the native implementation should be used instead.
Supported Pipeline Types: Not all Transformers pipeline types are currently supported for use with the python_function flavor. In particular, new model architectures may not be supported until the transformers library has a designated pipeline type in its supported pipeline implementations.
Input and Output Types: The input and output types for the python_function implementation may differ from those expected from the native pipeline. Users need to ensure compatibility with their data processing workflows.
Model Configuration: When saving or logging models, the model_config can be used to set certain parameters. However, if both model_config and a ModelSignature with parameters are saved, the default parameters in ModelSignature will override those in model_config.
Audio and Vision Models: Audio and text-based large language models are supported for use with pyfunc, while other types like computer vision and multi-modal models are only supported for native type loading.
Prompt Templates: Prompt templating is currently supported for a few pipeline types. For a full list of supported pipelines, and more information about the feature, see this link.
The currently supported pipeline types for Pyfunc can be seen here.
Detailed Documentation
To learn more about the nuances of the transformers flavor in MLflow, delve into the comprehensive guide, which covers:
View the Comprehensive GuideTransformers within MLflow: Explore the integration of the transformers library within MLflow and learn about its support for models, components, and pipelines.
Input and Output Types for PyFunc: Understand the standardization of input and output formats in the pyfunc model implementation for the flavor, ensuring seamless integration with JSON and Pandas DataFrames.
Supported Transformers Pipeline Types for Pyfunc: Familiarize yourself with the various
transformerspipeline types compatible with the pyfunc model flavor and their respective input and output data types.Using Model Config and Model Signature Params for `Transformers` Inference: Learn how to leverage
model_configandModelSignaturefor flexible and customized model loading and inference.Example of Loading a Transformers Model as a Python Function: Walk through a practical example demonstrating how to log, load, and interact with a pre-trained conversational model in MLflow.
Save and Load Options for Transformers: Explore the different approaches for saving model components or complete pipelines and understand the nuances of loading these models for various use cases.
Automatic Metadata and ModelCard Logging: Discover the automatic logging features for model cards and other metadata, enhancing model documentation and transparency.
Automatic Signature Inference: Learn about MLflow’s capability within the
transformersflavor to automatically infer and attach model signatures, facilitating easier model deployment.Scalability for Inference: Gain insights into optimizing
transformersmodels for inference, focusing on memory optimization and data type configurations.Input Data Types for Audio Pipelines: Understand the specific requirements for handling audio data in
transformerspipelines, including the handling of different input types likestr,bytes, andnp.ndarray.
Learn more about Transformers
Interested in learning more about how to leverage transformers for your machine learning workflows?
🤗 Hugging Face has a fantastic NLP course. Check it out and see how to leverage Transformers, Datasets, Tokenizers, and Accelerate.