Tracing Gemini
MLflow Tracing provides automatic tracing capability for Google Gemini. By enabling auto tracing
for Gemini by calling the mlflow.gemini.autolog() function, MLflow will capture nested traces and log them to the active MLflow Experiment upon invocation of Gemini Python SDK.
import mlflow
mlflow.gemini.autolog()
Current MLflow tracing integration supports both new Google GenAI SDK and legacy Google AI Python SDK. However, it may drop support for the legacy package without notice, and it is highly recommended to migrate your use cases to the new Google GenAI SDK.
MLflow trace automatically captures the following information about Gemini calls:
- Prompts and completion responses
- Latencies
- Model name
- Additional metadata such as
temperature,max_tokens, if specified. - Function calling if returned in the response
- Any exception if raised
Supported APIs
MLflow supports automatic tracing for the following Anthropic APIs:
| Text Generation | Chat | Function Calling | Streaming | Async | Image | Video |
|---|---|---|---|---|---|---|
| ✅ | ✅ | ✅ | - | ✅ (*1) | - | - |
(*1) Async support was added in MLflow 3.2.0.
To request support for additional APIs, please open a feature request on GitHub.
Basic Example
import mlflow
import google.genai as genai
import os
# Turn on auto tracing for Gemini
mlflow.gemini.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("Gemini")
# Configure the SDK with your API key.
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Use the generate_content method to generate responses to your prompts.
response = client.models.generate_content(
model="gemini-1.5-flash", contents="The opposite of hot is"
)
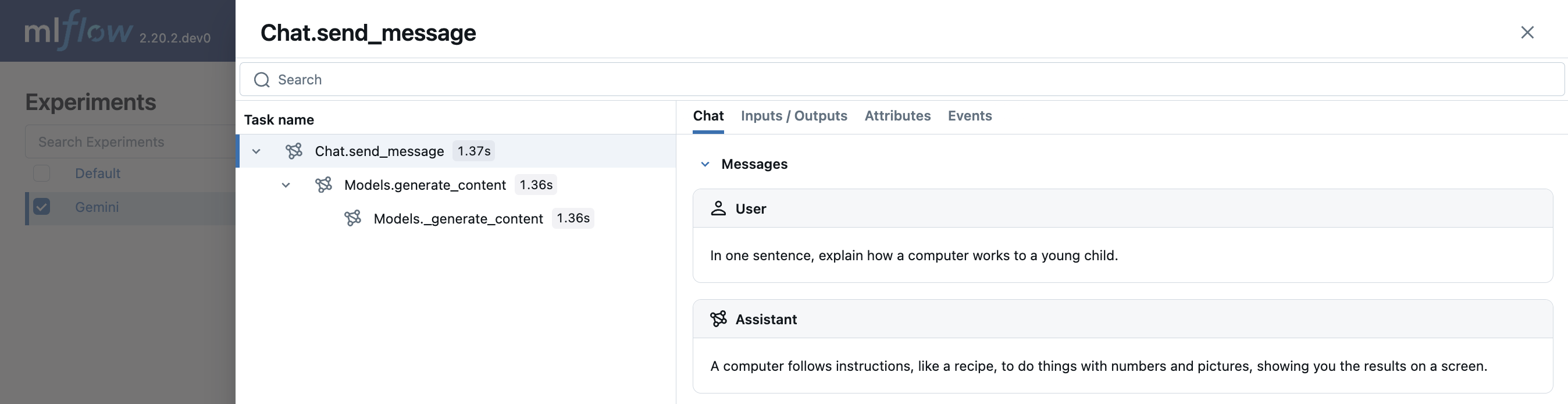
Multi-turn chat interactions
MLflow support tracing multi-turn conversations with Gemini:
import mlflow
mlflow.gemini.autolog()
chat = client.chats.create(model='gemini-1.5-flash')
response = chat.send_message("In one sentence, explain how a computer works to a young child.")
print(response.text)
response = chat.send_message("Okay, how about a more detailed explanation to a high schooler?")
print(response.text)
Async
MLflow Tracing supports asynchronous API of the Gemini SDK since MLflow 3.2.0. The usage is same as the synchronous API.
# Configure the SDK with your API key.
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Async API is invoked through the `aio` namespace.
response = await client.aio.models.generate_content(
model="gemini-1.5-flash", contents="The opposite of hot is"
)
Embeddings
MLflow Tracing for Gemini SDK supports embeddings API:
result = client.models.embed_content(model="text-embedding-004", contents="Hello world")
Disable auto-tracing
Auto tracing for Gemini can be disabled globally by calling mlflow.gemini.autolog(disable=True) or mlflow.autolog(disable=True).