Tracing Smolagents
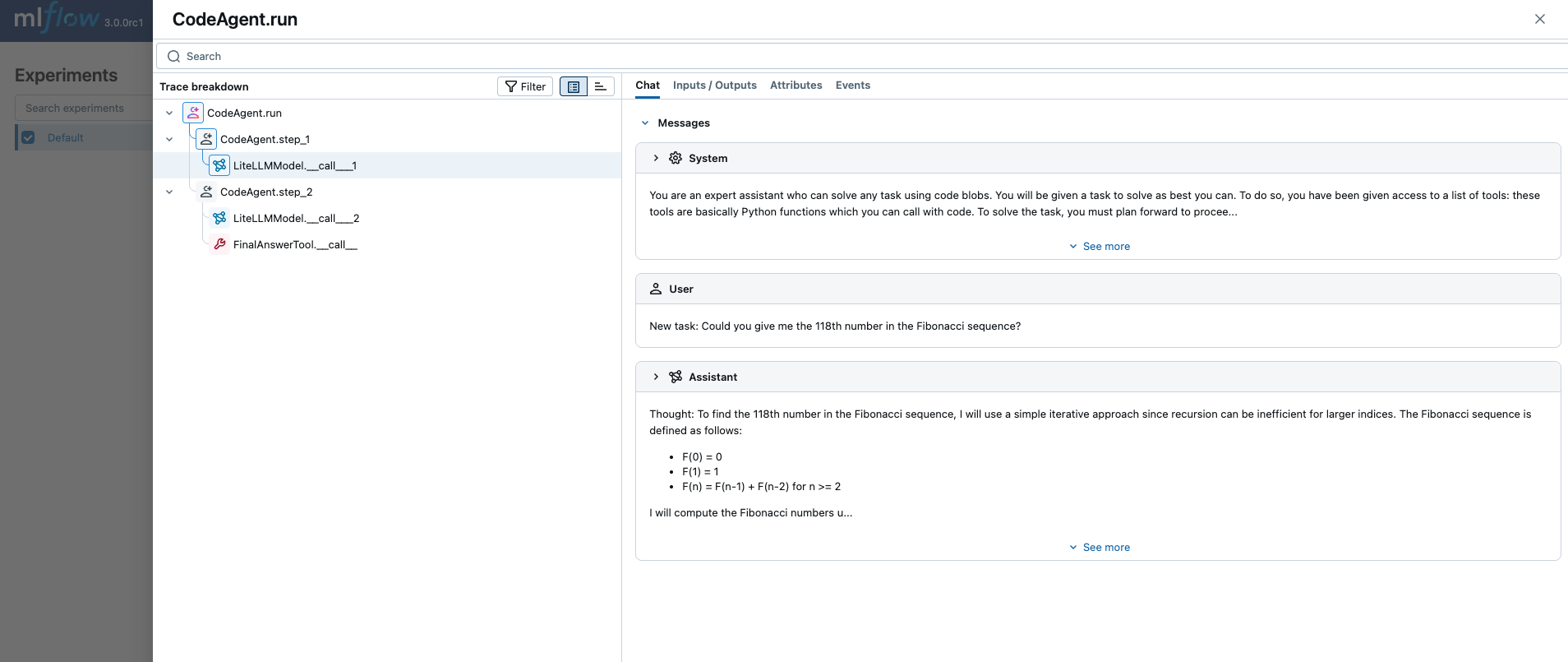
MLflow Tracing provides automatic tracing capability when using Smolagents.
When Smolagents auto-tracing is enabled by calling the mlflow.smolagents.autolog() function,
usage of the Smolagents SDK will automatically record generated traces during interactive development.
Note that only synchronous calls are supported, and that asynchronous API and streaming methods are not traced.
Example Usage
from smolagents import CodeAgent, LiteLLMModel
import mlflow
# Turn on auto tracing for Smolagents by calling mlflow.smolagents.autolog()
mlflow.smolagents.autolog()
model = LiteLLMModel(model_id="openai/gpt-4o-mini", api_key=API_KEY)
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
result = agent.run(
"Could you give me the 118th number in the Fibonacci sequence?",
)
Token usage
MLflow >= 3.2.0 supports token usage tracking for Smolagents. The token usage for each LLM call will be logged in the mlflow.chat.tokenUsage attribute. The total token usage throughout the trace will be
available in the token_usage field of the trace info object.
import json
import mlflow
mlflow.smolagents.autolog()
model = LiteLLMModel(model_id="openai/gpt-4o-mini", api_key=API_KEY)
agent = CodeAgent(tools=[], model=model, add_base_tools=True)
result = agent.run(
"Could you give me the 118th number in the Fibonacci sequence?",
)
# Get the trace object just created
last_trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id=last_trace_id)
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
== Total token usage: ==
Input tokens: 4360
Output tokens: 185
Total tokens: 4545
== Detailed usage for each LLM call: ==
LiteLLMModel.__call___1:
Input tokens: 2047
Output tokens: 124
Total tokens: 2171
LiteLLMModel.__call___2:
Input tokens: 2313
Output tokens: 61
Total tokens: 2374
Disable auto-tracing
Auto tracing for Smolagents can be disabled globally by calling mlflow.smolagents.autolog(disable=True) or mlflow.autolog(disable=True).