Evaluating LLMs/Agents with MLflow
MLflow's evaluation and monitoring capabilities help you systematically measure, improve, and maintain the quality of your GenAI applications throughout their lifecycle from development through production.
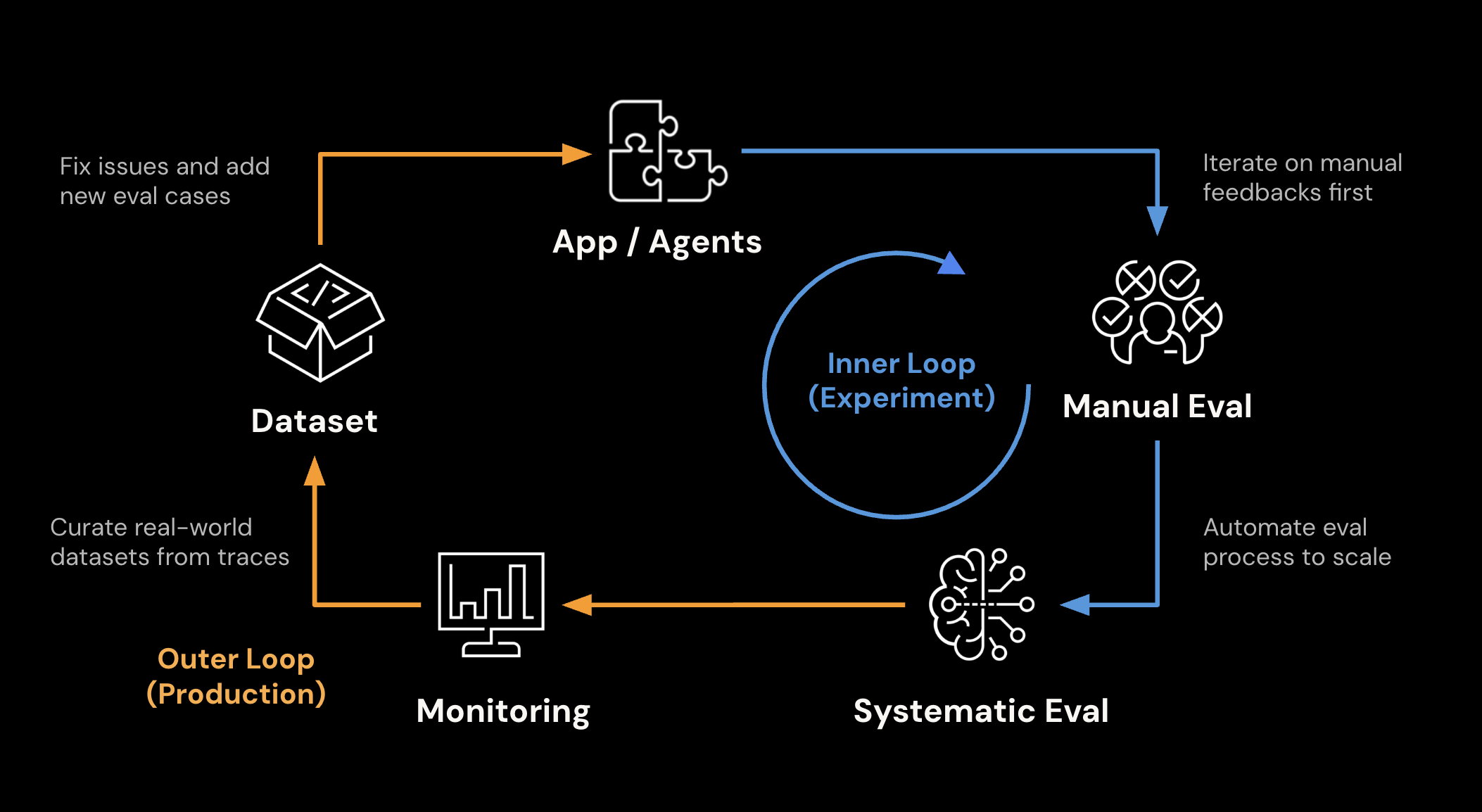
The tenet of MLflow's evaluation capabilities is Evaluation-Driven Development. This is an emerging practice to tackle the challenge of building high-quality LLM/Agentic applications. MLflow is an end-to-end platform that is designed to support this practice and help you deploy AI applications with confidence.
- Systematic Evaluation
- Human Feedback
- LLM-as-a-Judge
- Production Monitoring
- Dataset Collection
Evaluate and Enhance quality
Systematically assessing and improving the quality of GenAI applications is a challenge. MLflow provides a comprehensive set of tools to help you evaluate and enhance the quality of your applications.
Being the industry's most-trusted experiment tracking platform, MLflow provides a strong foundation for tracking your evaluation results and effectively collaborating with your team.
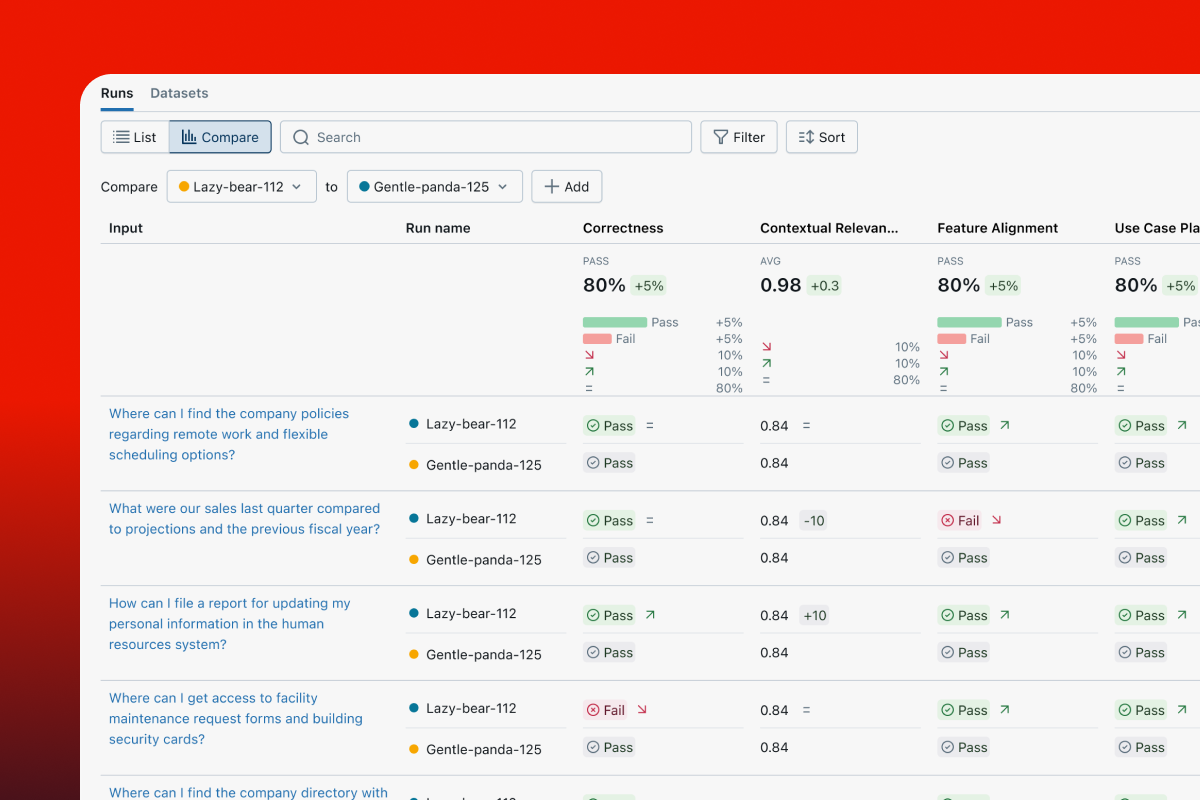
Track Annotation and Human Feedbacks
Human feedback is essential for building high-quality GenAI applications that meet user expectations. MLflow supports collecting, managing, and utilizing feedback from end-users and domain experts.
Feedbacks are attached to traces and recorded with metadata, including user, timestamp, revisions, etc.
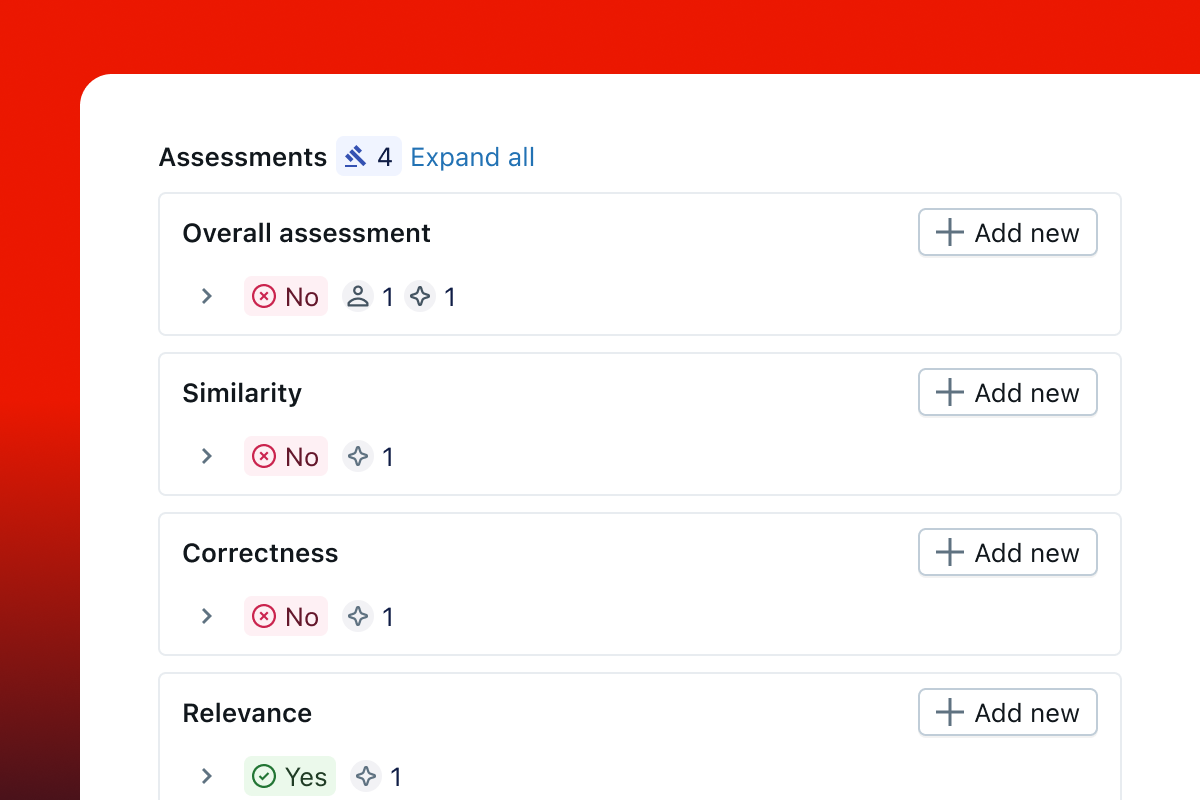
Scale Quality Assessment with Automation
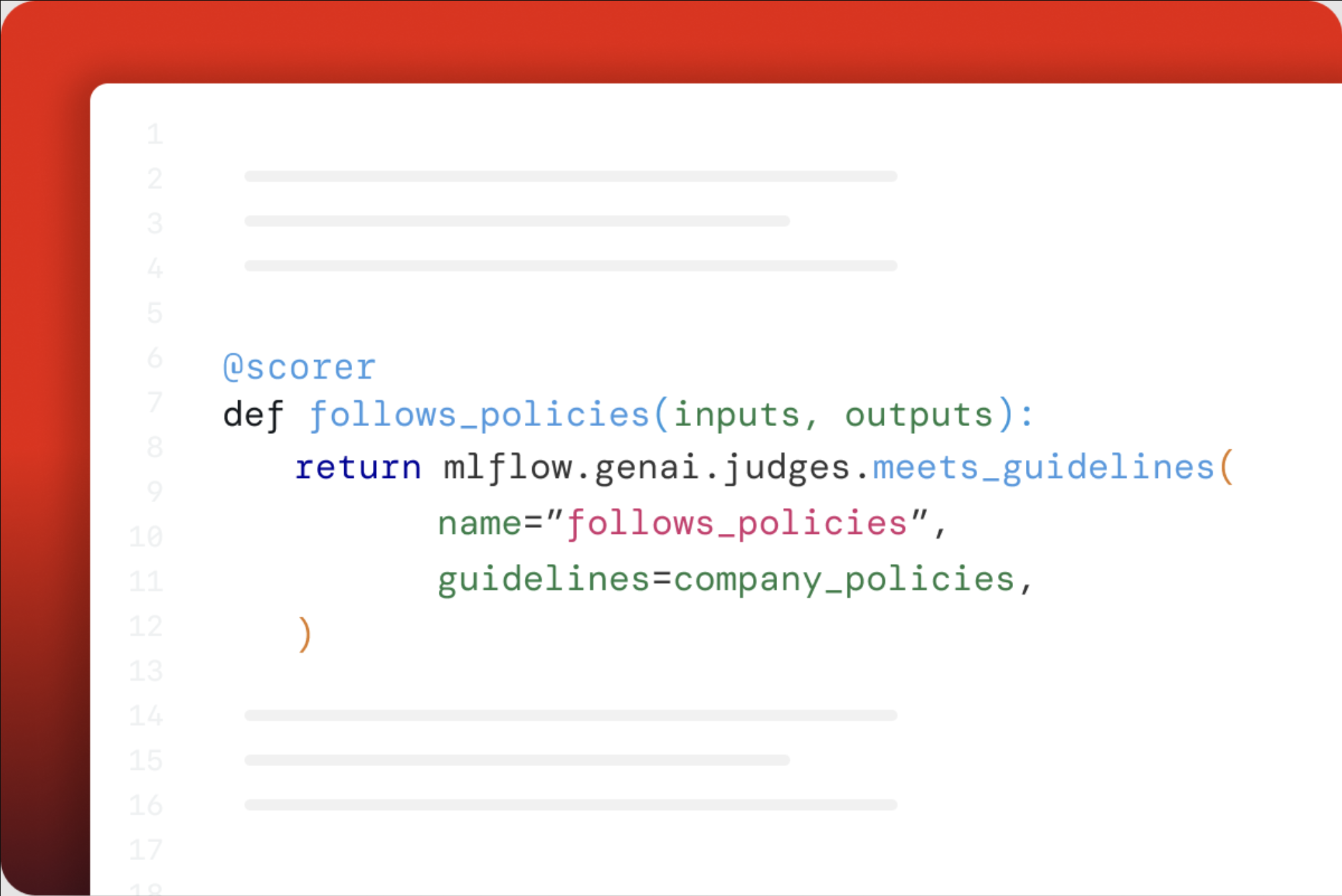
Quality assessment is a critical part of building high-quality GenAI applications, however, it is often time-consuming and requires human expertise. LLMs are powerful tools to automate quality assessment.
MLflow offers various built-in LLM-as-a-Judge scorers to help automate the process, as well as a flexible toolset to build your own LLM judges with ease.
Monitor Applications in Production
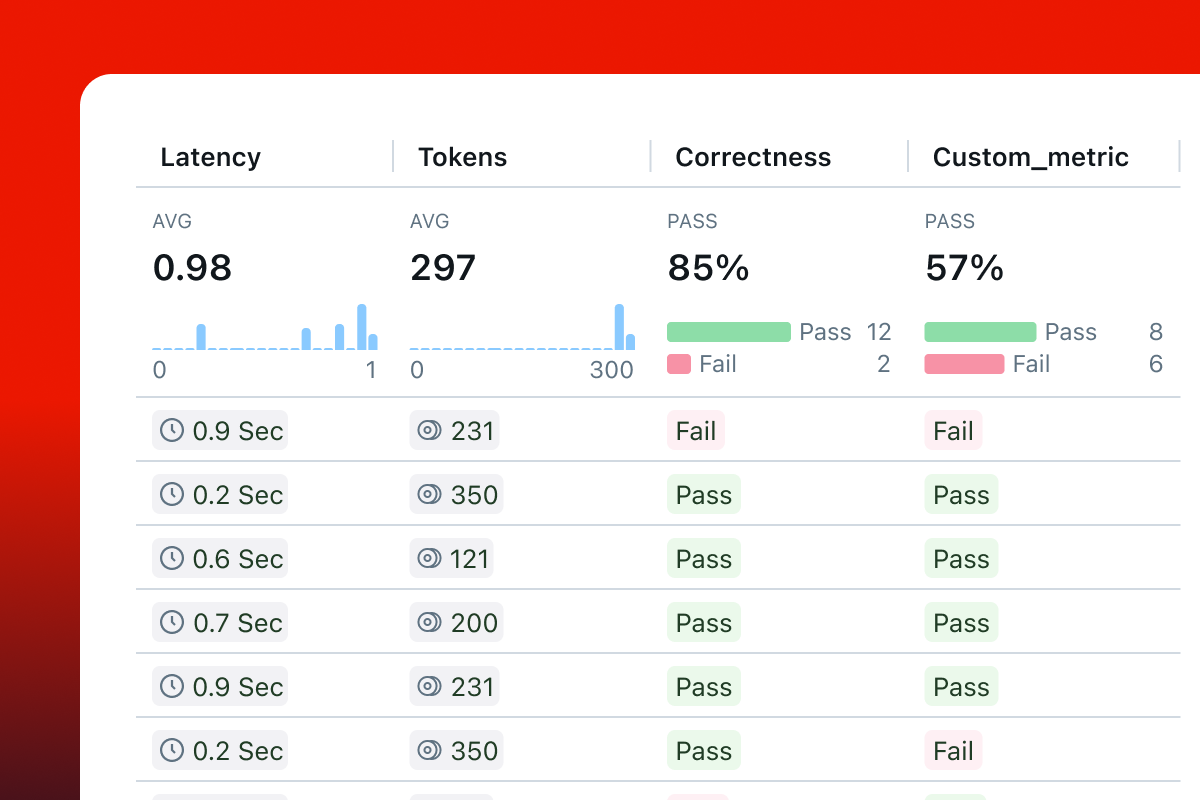
Understanding and optimizing GenAI application performance is crucial for efficient operations. MLflow Tracing captures key metrics like latency and token usage at each step, as well as various quality metrics, helping you identify bottlenecks, monitor efficiency, and find optimization opportunities.
Create a High-Quality Dataset from Real World Traffic
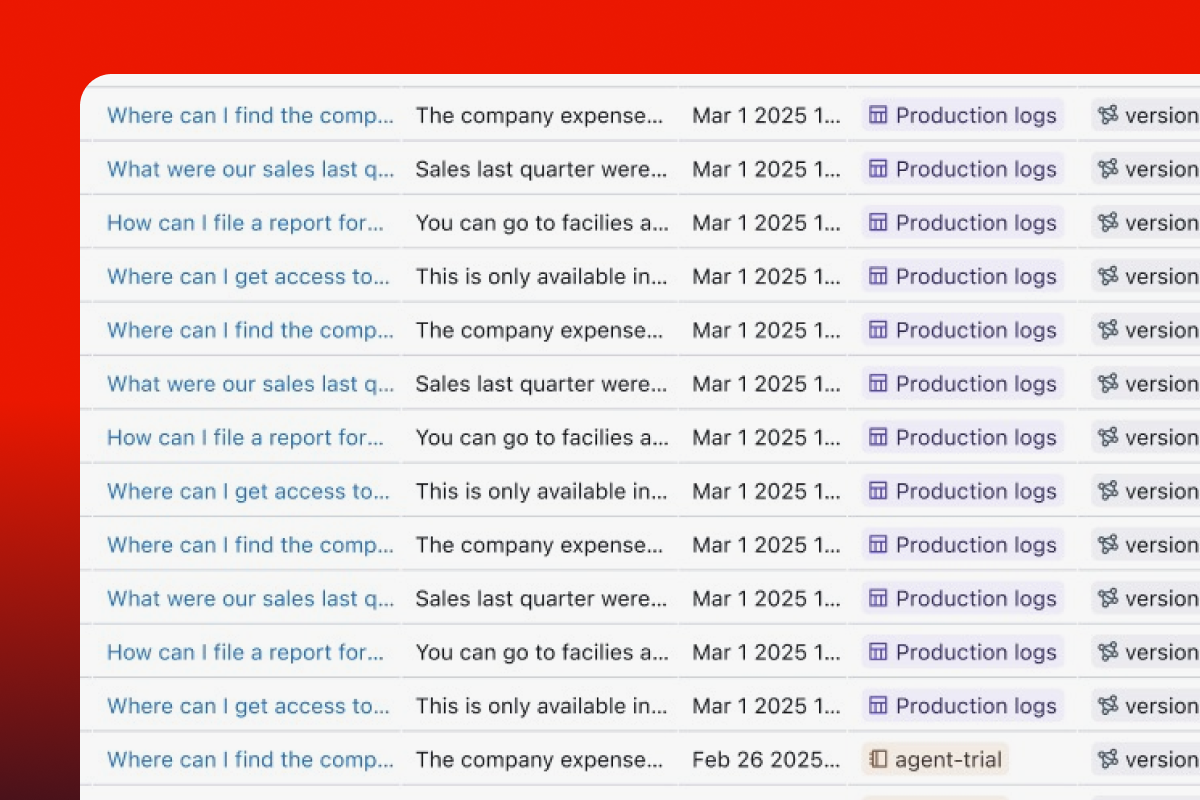
Evaluating the performance of your GenAI application is crucial, but creating a reliable evaluation dataset is challenging.
Traces from production systems capture perfect data for building high-quality datasets with precise details for internal components like retrievers and tools.
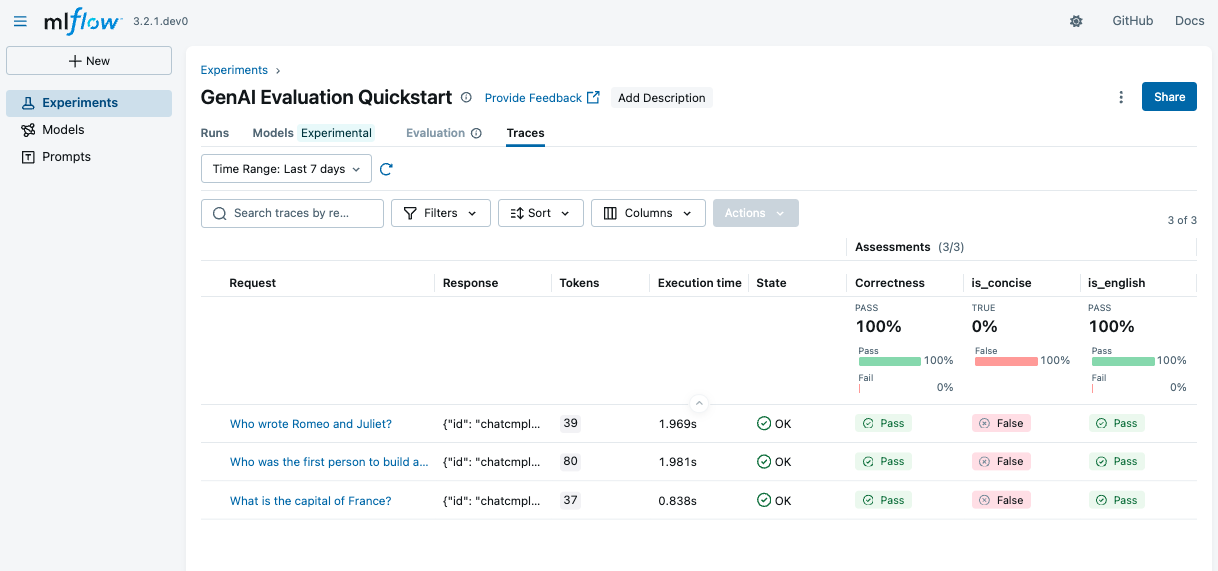
Running an Evaluation
Each evaluation is defined by three components:
| Component | Example |
|---|---|
| Dataset Inputs & expectations (and optionally pre-generated outputs and traces) | |
| Scorer Evaluation criteria | |
| Predict Function Generates outputs for the dataset | |
The following example shows a simple evaluation of a dataset of questions and expected answers.
import os
import openai
import mlflow
from mlflow.genai.scorers import Correctness, Guidelines
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. Define a simple QA dataset
dataset = [
{
"inputs": {"question": "Can MLflow manage prompts?"},
"expectations": {"expected_response": "Yes!"},
},
{
"inputs": {"question": "Can MLflow create a taco for my lunch?"},
"expectations": {
"expected_response": "No, unfortunately, MLflow is not a taco maker."
},
},
]
# 2. Define a prediction function to generate responses
def predict_fn(question: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": question}]
)
return response.choices[0].message.content
# 3.Run the evaluation
results = mlflow.genai.evaluate(
data=dataset,
predict_fn=predict_fn,
scorers=[
# Built-in LLM judge
Correctness(),
# Custom criteria using LLM judge
Guidelines(name="is_english", guidelines="The answer must be in English"),
],
)
Review the results
Open the MLflow UI to review the evaluation results. If you are using OSS MLflow, you can use the following command to start the UI:
mlflow ui --port 5000
If you are using cloud-based MLflow, open the experiment page in the platform.