Migrating from Legacy LLM Evaluation
This is a migration guide for users who are using the legacy LLM evaluation capability through mlflow.evaluate API and see the following warning while migrating to MLflow 3.
The mlflow.evaluate API has been deprecated as of MLflow 3.0.0.
If you are new to MLflow or its evaluation capabilities, start from the MLflow 3 Evaluation guide instead.
Why Migrate?
MLflow 3 introduces a new evaluation suite that is optimized for evaluating LLM applications and AI agents. Compared to the legacy evaluation through the mlflow.evaluate API, the new suite offers the following benefits:
1. Richer evaluation results
MLflow 3 displays the evaluation results with intuitive visualizations. Each prediction is recorded with a trace, which allows you to further investigate the result in details and identify the root cause of low quality predictions.
| Old Results | 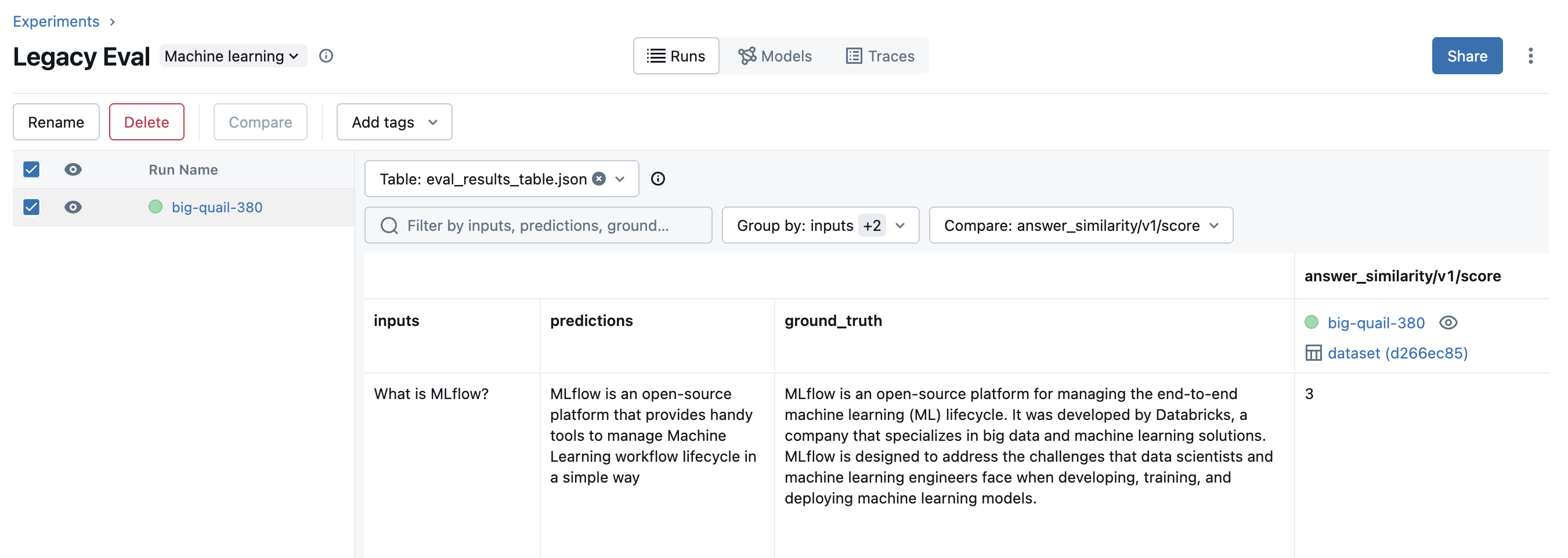 |
|---|---|
| New Results | 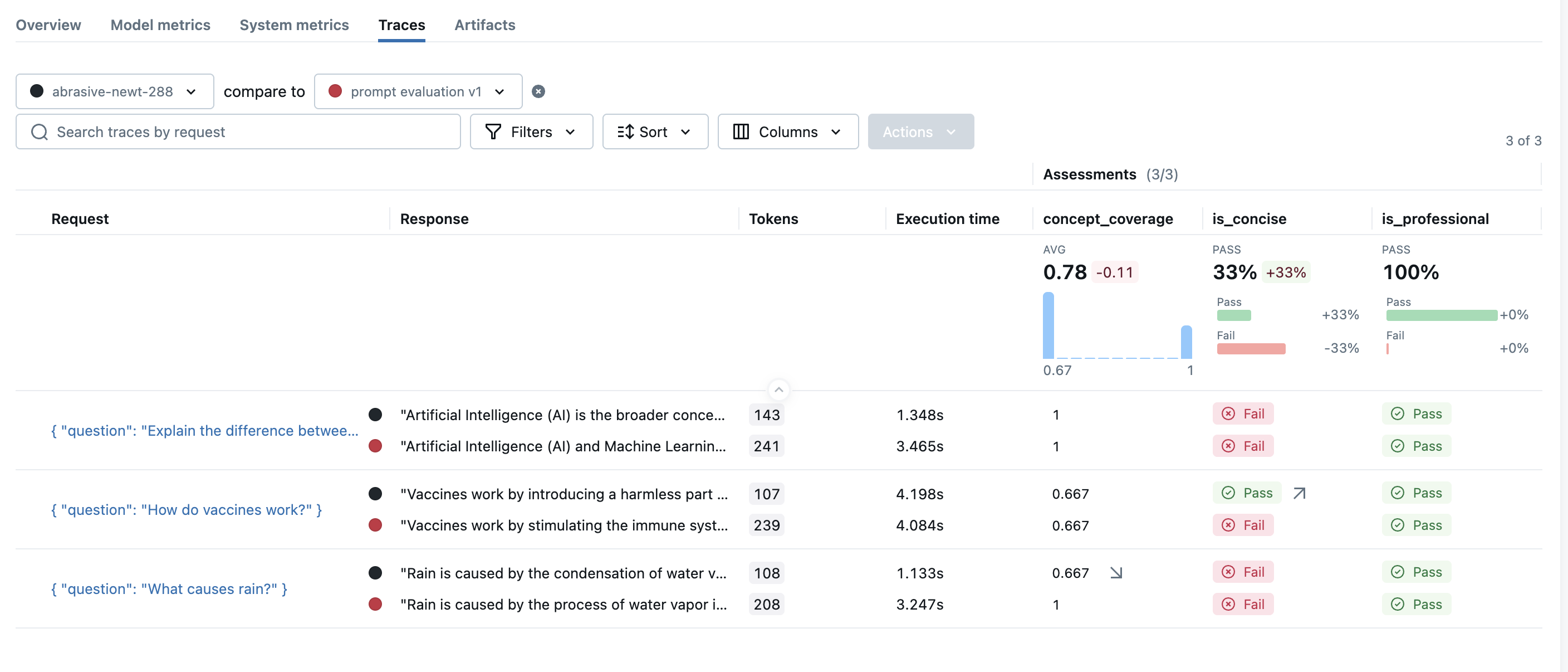 |
2. More powerful and flexible LLM-as-a-Judge
A rich set of built-in LLM Judges and a flexible toolset to build your own LLM-as-a-Judge supports you to evaluate various aspects of your LLM applications. Furthermore, the new Agents-as-a-Judge capability evaluates complex trace with minimum context window consumption and boilerplate code.
3. Integration with other MLflow capabilities
The new evaluation suite is tightly integrated with other MLflow capabilities, such as tracing, prompt management, prompt optimization, making it an end-to-end solution for building high-quality LLM applications.
4. Better future support
MLflow is rapidly evolving (changelog) and will continue strengthening its evaluation capabilities with the north star of Deliver production-ready AI. Migrating your workload to the new evaluation suite will ensure you have instant access to the latest and greatest features.
Migration Steps
Wrap your model in a function
If you are evaluating an MLflow Model, wrap the model in a function and pass it to the new evaluation API.
Update dataset format
Update the inputs and ground truth format to match the new evaluation dataset format.
Migrate metrics
Update the metrics to use the new built-in or custom scorers offered by MLflow 3.
Run evaluation
Execute the evaluation and make sure the results are as expected.
Before starting the migration, we highly recommend you to visit the Evaluation Guide and go through the Quickstart to get a sense of the new evaluation suite. Basic understanding of the concepts will help you to migrate your existing workload smoothly.
1. Wrap Your Model in a Function
The old evaluation API accepts MLflow model URI as an evaluation target. The new evaluation API accepts a callable function as predict_fn argument instead, to provide more flexibility and control. This also eliminates the need of logging the model in MLflow before evaluation.
| Old Format | New Format |
|---|---|
| |
If you want to evaluate a pre-logged model with the new evaluation API, simply call the loaded model in the function.
# IMPORTANT: Load the model outside the predict_fn function. Otherwise the model will be loaded
# for each input in the dataset and significantly slow down the evaluation.
model = mlflow.pyfunc.load_model(model_uri)
def predict_fn(question: str) -> str:
return model.predict([question])[0]
2. Update the Dataset Format
The dataset format has been changed to be more flexible and consistent. The new format requirements are:
inputs: The input to the predict_fn function. The key(s) must match the parameter name of the predict_fn function.expectations: The expected output from the predict_fn function, namely, ground truth for the answer.- Optionally, you can pass
outputscolumn ortracecolumn to evaluate pre-generated outputs and traces.
| Old Format | New Format |
|---|---|
| |
3. Migrate Metrics
The new evaluation API supports a rich set of built-in and custom LLM-as-a-Judge metrics. The table below shows the mapping between the legacy metrics and the new metrics.
| Metric | Before | After |
|---|---|---|
| Latency | latency | Traces record latency and also span-level break down. You don't need to specify a metric to evaluate latency when running the new mlflow.genai.evaluate() API. |
| Token Count | token_count | Traces record token count for LLM calls for most of popular LLM providers. For other cases, you can use a custom scorer to calculate the token count. |
| Heuristic NLP metrics | toxicity, flesch_kincaid_grade_level, ari_grade_level, exact_match, rouge1, rouge2, rougeL, rougeLsum | Use a Code-based Scorer to implement the equivalent metrics. See the example below for reference. |
| Retrieval metrics | precision_at_k, recall_at_k, ndcg_at_k | Use the new built-in retrieval metrics or define a custom code-based scorer. |
| Built-in LLM-as-a-Judge metrics | answer_similarity, answer_correctness, answer_relevance, relevance, faithfulness | Use the new built-in judges. If the metric is not supported out of the box, define a custom LLM-as-a-Judge scorer using the make_judge API, following the example below. |
| Custom LLM-as-a-Judge metrics | make_genai_metric, make_genai_metric_from_prompt | Use the make_judge API to define a custom LLM-as-a-Judge scorer, following the example below. |
Example of custom LLM-as-a-Judge metrics
The new evaluation API supports defining custom LLM-as-a-Judge metrics from a custom prompt template. This eliminates a lot of complexity and over-abstractions from the previous make_genai_metric and make_genai_metric_from_prompt APIs.
from mlflow.genai import make_judge
answer_similarity = make_judge(
name="answer_similarity",
instructions=(
"Evaluated on the degree of semantic similarity of the provided output to the expected answer.\n\n"
"Output: {{ outputs }}\n\n"
"Expected: {{ expectations }}"
),
feedback_value_type=int,
)
# Pass the scorer to the evaluation API.
mlflow.genai.evaluate(scorers=[answer_similarity, ...])
See the LLM Judges guide for more details.
Example of custom heuristic metrics
Implementing a custom scorer for heuristic metrics is straightforward. You just need to define a function and decorate it with the @scorer decorator. The example below shows how to implement the exact_match metric.
@scorer
def exact_match(outputs: dict, expectations: dict) -> bool:
return outputs == expectations["expected_response"]
# Pass the scorer to the evaluation API.
mlflow.genai.evaluate(scorers=[exact_match, ...])
See the Code-based Scorers guide for more details.
4. Run Evaluation
Now you have migrated all components of the legacy evaluation API and are ready to run the evaluation!
mlflow.genai.evaluate(
data=eval_data,
predict_fn=predict_fn,
scorers=[answer_similarity, exact_match, ...],
)
To view the evaluation results, click the link in the console output, or navigate to the Evaluations tab in the MLflow UI.
Other Changes
- When using Databricks Model Serving endpoint as a LLM-judge model, use
databricks:/<endpoint-name>as model provider, rather thanendpoints:/<endpoint-name> - The evaluation results are shown in the
Evaluationstab in the MLflow UI. - Lots of configuration knobs such as
model_type,targets,feature_names,env_manager, are removed in the new evaluation API.
FAQ
Q: The feature I want is not supported in the new evaluation suite.
Please open an feature request in GitHub.
Q: Where can I find the documentation for the legacy evaluation API?
See MLflow 2 documentation for the legacy evaluation API.
Q: When will the legacy evaluation API be removed?
It will likely be removed in MLflow 3.7.0 or a few releases after that.
Q: Should I migrate non-LLM workloads to the new evaluation suite?
No. The new evaluation suite is only for LLM applications and AI agents. If you are not building LLM applications or AI agents, you should use the mlflow.models.evaluate() API, which offers perfect compatibility with mlflow.evaluate API but drops the LLM-specific features.