Create custom code-based scorers
Custom code-based scorers offer the ultimate flexibility to define precisely how your LLM application or AI agent's quality is measured. You can define evaluation metrics tailored to your specific business use case, whether based on simple heuristics, advanced logic, or programmatic evaluations.
Use custom scorers for the following scenarios:
- Defining a custom heuristic or code-based evaluation metric.
- Customizing how the data from your app's trace is mapped to MLflow's research-backed LLM judges.
- Using your own LLM for evaluation.
- Any other use cases where you need more flexibility and control than provided by custom LLM judges.
For a tutorial with many examples, see Code-based scorer examples.
Custom code-based scorers (both the @scorer decorator and the Scorer class) work with mlflow.genai.evaluate() for offline evaluation. They are not supported for automatic evaluation (production monitoring), which only supports LLM judges such as built-in judges, make_judge(), and Guidelines.
How custom scorers work
Custom scorers are written in Python and give you full control to evaluate any data from your app's traces. After you define a custom scorer, you can use it with mlflow.genai.evaluate() just like a built-in LLM Judge.
For example, suppose you want a scorer that checks if the LLM's response exactly matches the expected_response and is short enough. The image of the MLflow UI below shows traces scored by these custom metrics.
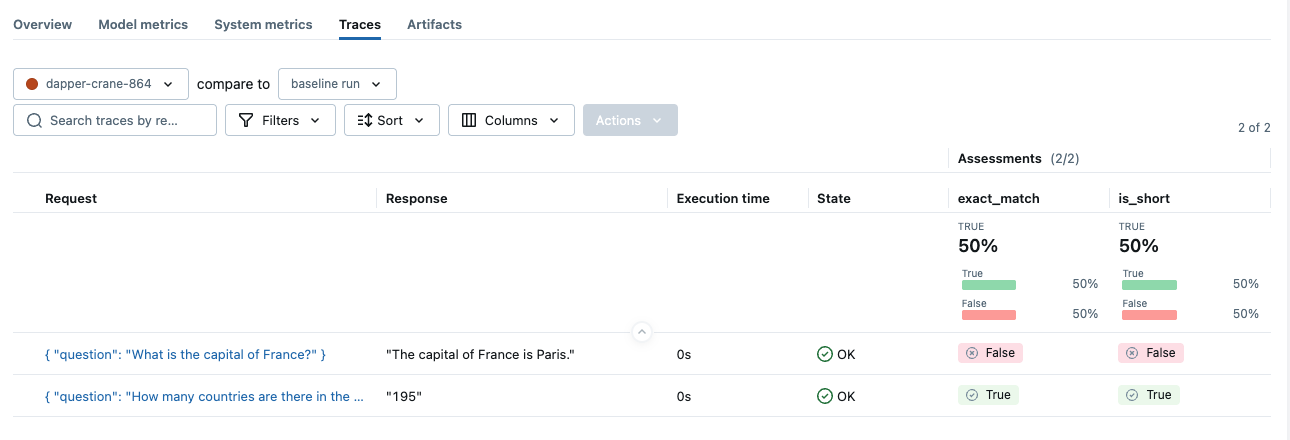
The code snippet below defines these custom scorers and uses it with mlflow.genai.evaluate():
from mlflow.genai import scorer
from mlflow.entities import Feedback
@scorer
def exact_match(outputs: dict, expectations: dict) -> bool:
return outputs == expectations["expected_response"]
@scorer
def is_short(outputs: dict) -> Feedback:
score = len(outputs.split()) <= 5
rationale = (
"The response is short enough."
if score
else f"The response is not short enough because it has ({len(outputs.split())} words)."
)
return Feedback(value=score, rationale=rationale)
eval_dataset = [
{
"inputs": {"question": "How many countries are there in the world?"},
"outputs": "195",
"expectations": {"expected_response": "195"},
},
{
"inputs": {"question": "What is the capital of France?"},
"outputs": "The capital of France is Paris.",
"expectations": {"expected_response": "Paris"},
},
]
mlflow.genai.evaluate(
data=eval_dataset,
scorers=[exact_match, is_short],
)
The example above illustrates a common pattern for code-based scorers:
- The
@scorerdecorator is used to define the scorer. - The input to this scorer is the full trace, giving it access to the AI app's inputs, intermediate spans, and outputs.
- Scorer logic can be fully custom. You can call LLMs or other scorers.
- The output of this scorer is a rich
Feedbackobject with values and explanations. - The metric name is
llm_response_time_good, matching the scorer function name.
This pattern is just one possibility for code-based scorers. The rest of this article explains options for defining custom scorers.
Define scorers with the @scorer decorator
Most code-based scorers should be defined using the @scorer decorator. Below is the signature for such scorers, illustrating possible inputs and outputs.
from mlflow.genai.scorers import scorer
from typing import Optional, Any
from mlflow.entities import Feedback
@scorer
def my_custom_scorer(
*, # All arguments are keyword-only
inputs: Optional[
dict[str, Any]
], # App's raw input, a dictionary of input argument names and values
outputs: Optional[Any], # App's raw output
expectations: Optional[dict[str, Any]], # Ground truth, a dictionary of label names and values
trace: Optional[mlflow.entities.Trace], # Complete trace with all spans and metadata
) -> Union[int, float, bool, str, Feedback, List[Feedback]]:
# Your evaluation logic here
...
For more flexibility than the @scorer decorator allows, you can instead define scorers using the Scorer class.
Inputs
Scorers receive the complete MLflow trace containing all spans, attributes, and outputs. As a convenience, MLflow also extracts commonly needed data and passes it as named arguments. All input arguments are optional, so declare only what your scorer needs:
inputs: The request sent to your app (e.g., user query, context).outputs: The response from your app (e.g., generated text, tool calls)expectations: Ground truth or labels (e.g., expected response, guidelines, etc.)trace: The complete MLflow trace with all spans, allowing analysis of intermediate steps, latency, tool usage, and more. The trace is passed to the custom scorer as an instantiatedmlflow.entities.Traceclass class.
When running mlflow.genai.evaluate(), the inputs, outputs, and expectations parameters can be specified in the data argument, or parsed from the trace.
Outputs
Scorers can return different types of simple values or rich Feedback objects depending on your evaluation needs.
| Return Type | MLflow UI Display | Use Case |
|---|---|---|
"yes"/"no" | Pass/Fail | Binary evaluation |
True/False | True/False | Boolean checks |
int/float | Numeric value | Scores, counts |
Feedback | Value + rationale | Detailed assessment |
| List[Feedback] | Multiple metrics | Multi-aspect evaluation |
Simple values
Output primitive values for straightforward pass/fail or numeric assessments. Below are simple scorers for an AI app that returns a string as a response.
@scorer
def response_length(outputs: str) -> int:
# Return a numeric metric
return len(outputs.split())
@scorer
def contains_citation(outputs: str) -> str:
# Return pass/fail string
return "yes" if "[source]" in outputs else "no"
Rich feedback
Return a Feedback object or list of Feedback objects for detailed assessments with scores, rationales, and metadata.
from mlflow.entities import Feedback, AssessmentSource
@scorer
def content_quality(outputs):
return Feedback(
value=0.85, # Can be numeric, boolean, string, or other types
rationale="Clear and accurate, minor grammar issues",
# Optional: source of the assessment. Several source types are supported,
# such as "HUMAN", "CODE", "LLM_JUDGE".
source=AssessmentSource(source_type="HUMAN", source_id="grammar_checker_v1"),
# Optional: additional metadata about the assessment.
metadata={
"annotator": "me@example.com",
},
)
Multiple feedback objects can be returned as a list. Each feedback should have the name field specified, and those names will be displayed as separate metrics in the evaluation results.
@scorer
def comprehensive_check(inputs, outputs):
return [
Feedback(name="relevance", value=True, rationale="Directly addresses query"),
Feedback(name="tone", value="professional", rationale="Appropriate for audience"),
Feedback(name="length", value=150, rationale="Word count within limits"),
]
Metric naming behavior
As you define scorers, use clear, consistent names that indicate the scorer's purpose. These names will appear as metric names in your evaluation and dashboards. Follow MLflow naming conventions such as safety_check or relevance_monitor.
When you define scorers using either the @scorer decorator or the Scorer class, the metric names in the evaluation runs created by evaluation and monitoring follow simple rules:
- If the scorer returns one or more
Feedbackobjects, thenFeedback.namefields take precedence, if specified. - For primitive return values or unnamed
Feedbacks, the function name (for the@scorerdecorator) or theScorer.namefield (for theScorerclass) are used.
Expanding these rules to all possibilities gives the following table for metric naming behavior:
| Return value | @scorer decorator behavior | Scorer class behavior |
|---|---|---|
Primitive value (int, float, str) | Function name | name field |
| Feedback without name | Function name | name field |
| Feedback with name | Feedback name | Feedback name |
List[Feedback] with names | Feedback names | Feedback names |
For evaluation, it is important that all metrics have distinct names. If a scorer returns List[Feedback], then each Feedback in the List must have a distinct name.
See examples of naming behavior in the tutorial.
Parsing Traces for Scoring
Scorers that accept a trace parameter cannot be used with pandas DataFrames. They require actual execution traces from your application.
If you need to evaluate static data (e.g., a CSV file with pre-generated responses), use field-based scorers that work with inputs, outputs, and expectations parameters only.
Scorers have access to the complete MLflow traces, including spans, attributes, and outputs, allowing you to evaluate the agent's behavior precisely, not just the final output.
The Trace.search_spans API is a powerful way to retrieve such intermediate information from the trace.
Open the tabs below to see examples of custom scorers that evaluate the detailed behavior of agents by parsing the trace.
- Retrieved Document Recall
- Tool Call Trajectory
- Sub-Agents Routing
Example 1: Evaluating Retrieved Documents Recall
from mlflow.entities import SpanType, Trace
from mlflow.genai import scorer
@scorer
def retrieved_document_recall(trace: Trace, expectations: dict) -> Feedback:
# Search for retriever spans in the trace
retriever_spans = trace.search_spans(span_type=SpanType.RETRIEVER)
# If there are no retriever spans
if not retriever_spans:
return Feedback(
value=0,
rationale="No retriever span found in the trace.",
)
# Gather all retrieved document URLs from the retriever spans
all_document_urls = []
for span in retriever_spans:
all_document_urls.extend([document["doc_uri"] for document in span.outputs])
# Compute the recall
true_positives = len(set(all_document_urls) & set(expectations["relevant_document_urls"]))
expected_positives = len(expectations["relevant_document_urls"])
recall = true_positives / expected_positives
return Feedback(
value=recall,
rationale=f"Retrieved {true_positives} relevant documents out of {expected_positives} expected.",
)
Example 2: Evaluating Tool Call Trajectory
from mlflow.entities import SpanType, Trace
from mlflow.genai import scorer
@scorer
def tool_call_trajectory(trace: Trace, expectations: dict) -> Feedback:
# Search for tool call spans in the trace
tool_call_spans = trace.search_spans(span_type=SpanType.TOOL)
# Compare the tool trajectory with expectations
actual_trajectory = [span.name for span in tool_call_spans]
expected_trajectory = expectations["tool_call_trajectory"]
if actual_trajectory == expected_trajectory:
return Feedback(value=1, rationale="The tool call trajectory is correct.")
else:
return Feedback(
value=0,
rationale=(
"The tool call trajectory is incorrect.\n"
f"Expected: {expected_trajectory}.\n"
f"Actual: {actual_trajectory}."
),
)
Example 3: Evaluating Sub-Agents Routing
from mlflow.entities import SpanType, Trace
from mlflow.genai import scorer
@scorer
def is_routing_correct(trace: Trace, expectations: dict) -> Feedback:
# Search for sub-agent spans in the trace
sub_agent_spans = trace.search_spans(span_type=SpanType.AGENT)
invoked_agents = [span.name for span in sub_agent_spans]
expected_agents = expectations["expected_agents"]
if invoked_agents == expected_agents:
return Feedback(value=True, rationale="The sub-agents routing is correct.")
else:
return Feedback(
value=False,
rationale=(
"The sub-agents routing is incorrect.\n"
f"Expected: {expected_agents}.\n"
f"Actual: {invoked_agents}."
),
)
Error handling
When a scorer encounters an error for a trace, MLflow can capture error details for that trace and then continue executing gracefully. For capturing error details, MLflow provides two approaches:
- Let exceptions propagate (recommended) so that MLflow can capture error messages for you.
- Handle exceptions explicitly.
Let exceptions propagate (recommended)
The simplest approach is to let exceptions throw naturally. MLflow automatically captures the exception and creates a Feedback object with the following error details:
value:Noneerror: The exception details, such as exception object, error message, and stack trace
The error information is displayed in the evaluation results. Open the corresponding row to see the error details.
Handle exceptions explicitly
For custom error handling or to provide specific error messages, catch exceptions and return a Feedback with None value and error details:
import json
from mlflow.entities import AssessmentError, Feedback
@scorer
def is_valid_response(outputs):
try:
data = json.loads(outputs)
required_fields = ["summary", "confidence", "sources"]
missing = [f for f in required_fields if f not in data]
if missing:
return Feedback(
error=AssessmentError(
error_code="MISSING_REQUIRED_FIELDS",
error_message=f"Missing required fields: {missing}",
),
)
return Feedback(value=True, rationale="Valid JSON with all required fields")
except json.JSONDecodeError as e:
return Feedback(error=e) # Can pass exception object directly to the error parameter
The error parameter accepts:
- Python Exception: Pass the exception object directly
AssessmentError(): For structured error reporting with error codes
Define scorers with the Scorer class
The @scorer decorator described above is simple and generally recommended, but when it is insufficient, you can instead use the Scorer base class. Class-based definitions allow for more complex scorers, especially scorers that require state. The Scorer class is a Pydantic object, so you can define additional fields and use them in the __call__ method.
You must define the name field to set the metric name. If you return a list of Feedback objects, then you must set the name field in each Feedback to avoid naming conflicts.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional
# Scorer class is a Pydantic object
class CustomScorer(Scorer):
# The `name` field is mandatory
name: str = "response_quality"
# Define additional fields
my_custom_field_1: int = 50
my_custom_field_2: Optional[list[str]] = None
# Override the __call__ method to implement the scorer logic
def __call__(self, outputs: str) -> Feedback:
# Your logic here
return Feedback(value=True, rationale="Response meets all quality criteria")
State management
When writing scorers using the Scorer class, be aware of rules for managing state with Python classes. In particular, be sure to use instance attributes, not mutable class attributes. The example below illustrates mistakenly sharing state across scorer instances.
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
# WRONG: Don't use mutable class attributes
class BadScorer(Scorer):
results = [] # Shared across all instances!
name: str = "bad_scorer"
def __call__(self, outputs, **kwargs):
self.results.append(outputs) # Causes issues
return Feedback(value=True)
# CORRECT: Use instance attributes
class GoodScorer(Scorer):
results: list[str] = None
name: str = "good_scorer"
def __init__(self):
self.results = [] # Per-instance state
def __call__(self, outputs, **kwargs):
self.results.append(outputs) # Safe
return Feedback(value=True)