Track versions of Git-based applications with MLflow
- This feature is experimental and may change in future releases.
- This feature is not supported in Databricks Git Folders yet due to limitations in accessing Git metadata.
- MLflow >= 3.4 is required for this feature.
This guide demonstrates how to track versions of your LLM application or AI agent when your app's code resides in Git or a similar version control system. MLflow provides automatic Git-based versioning through the mlflow.genai.enable_git_model_versioning() API, which seamlessly tracks your application versions based on Git state.
When enabled, MLflow automatically:
- Creates or reuses a LoggedModel based on your current git state
- Links all traces to this
LoggedModelversion - Captures Git metadata including diffs for uncommitted changes
- Manages version transitions as your code evolves
Git State Tracked by MLflow
MLflow tracks three key components of your Git state:
- Branch: The Git branch name (e.g.,
main,feature-xyz) - Commit: The Git commit hash uniquely identifying the code version
- Dirty State: Whether your working directory has uncommitted changes. A "dirty" repository means there are modifications that haven't been committed yet. MLflow captures these changes as a diff to ensure complete reproducibility
Why Git-Based Versioning Works for LLM Applications and AI Agents
Git-based versioning transforms your version control system into a powerful application lifecycle management tool. Every commit becomes a potential application version, with complete code history and change tracking built-in.
Commit-Based Versioning
Use Git commit hashes as unique version identifiers. Each commit represents a complete application state with full reproducibility.
Branch-Based Development
Leverage Git branches for parallel development. Feature branches become isolated version streams that can be merged systematically.
Automatic Metadata Capture
MLflow automatically captures Git commit, branch, and repository URL during runs. No manual version tracking required.
Seamless Integration
Works naturally with your existing Git workflow. No changes to development process or additional tooling required.
How MLflow Captures Git Context
With mlflow.genai.enable_git_model_versioning(), MLflow automatically manages version tracking based on your Git state. Each unique combination of branch, commit, and dirty state creates or reuses a LoggedModel version.
Automatic Git Detection
MLflow detects Git repositories and automatically captures commit hash, branch name, repository URL, and uncommitted changes.
Zero-Configuration Versioning
Simply call enable_git_model_versioning() once—MLflow handles all version management and trace linking automatically.
Smart Version Deduplication
MLflow intelligently reuses existing LoggedModels when Git state matches, avoiding version proliferation.
Prerequisites
Install MLflow and required packages:
pip install 'mlflow[genai]>=3.4' openai
Set your OpenAI API key:
export OPENAI_API_KEY="your-api-key-here"
Create an MLflow experiment by following the getting started guide.
Step 1: Enable Git-based version tracking
The simplest way to enable Git-based version tracking is to call mlflow.genai.enable_git_model_versioning() at the start of your application:
import mlflow
# Enable Git-based version tracking
# This automatically creates/reuses a LoggedModel based on your Git state
context = mlflow.genai.enable_git_model_versioning()
# Check which version is active
print(f"Active version - Branch: {context.info.branch}, Commit: {context.info.commit[:8]}")
print(f"Repository dirty: {context.info.dirty}")
You can also use it as a context manager for scoped versioning:
with mlflow.genai.enable_git_model_versioning() as context:
# All traces within this block are linked to the Git-based version
# Your application code here
...
# Version tracking is automatically disabled when exiting the context
Step 2: Create your application
Now let's create a simple application that will be automatically versioned:
import mlflow
import openai
# Enable Git-based version tracking
context = mlflow.genai.enable_git_model_versioning()
# Enable MLflow's autologging to instrument your application with Tracing
mlflow.openai.autolog()
# Set up OpenAI client
client = openai.OpenAI()
# Use the trace decorator to capture the application's entry point
@mlflow.trace
def my_app(input: str) -> str:
"""Customer support agent application"""
# This call is automatically instrumented by `mlflow.openai.autolog()`
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful customer support agent."},
{"role": "user", "content": input},
],
temperature=0.7,
max_tokens=150,
)
return response.choices[0].message.content
# Test the application - traces are automatically linked to the Git version
result = my_app(input="What is MLflow?")
print(result)
When you run this code, MLflow automatically:
- Detects your Git repository state (branch, commit, dirty status)
- Creates or reuses a LoggedModel matching this state
- Links all traces to this version
- Captures uncommitted changes as diffs if the repository is dirty
Step 3: Test version tracking with code changes
Run your application and observe how versions are tracked:
# Initial run - creates a LoggedModel for current Git state
result = my_app(input="What is MLflow?")
print(result)
result = my_app(input="What is Databricks?")
print(result)
# Both traces are linked to the same version since Git state hasn't changed
To see how MLflow tracks changes, modify your code (without committing) and run again:
# Make a change to your application code (e.g., modify temperature)
# The repository is now "dirty" with uncommitted changes
# Re-enable versioning - MLflow will detect the dirty state
context = mlflow.genai.enable_git_model_versioning()
print(f"Repository dirty: {context.info.dirty}") # Will show True
# This trace will be linked to a different version (same commit but dirty=True)
result = my_app(input="What is GenAI?")
print(result)
MLflow creates distinct versions for:
- Different Git branches
- Different commits
- Clean vs. dirty repository states
This ensures complete reproducibility of your application versions.
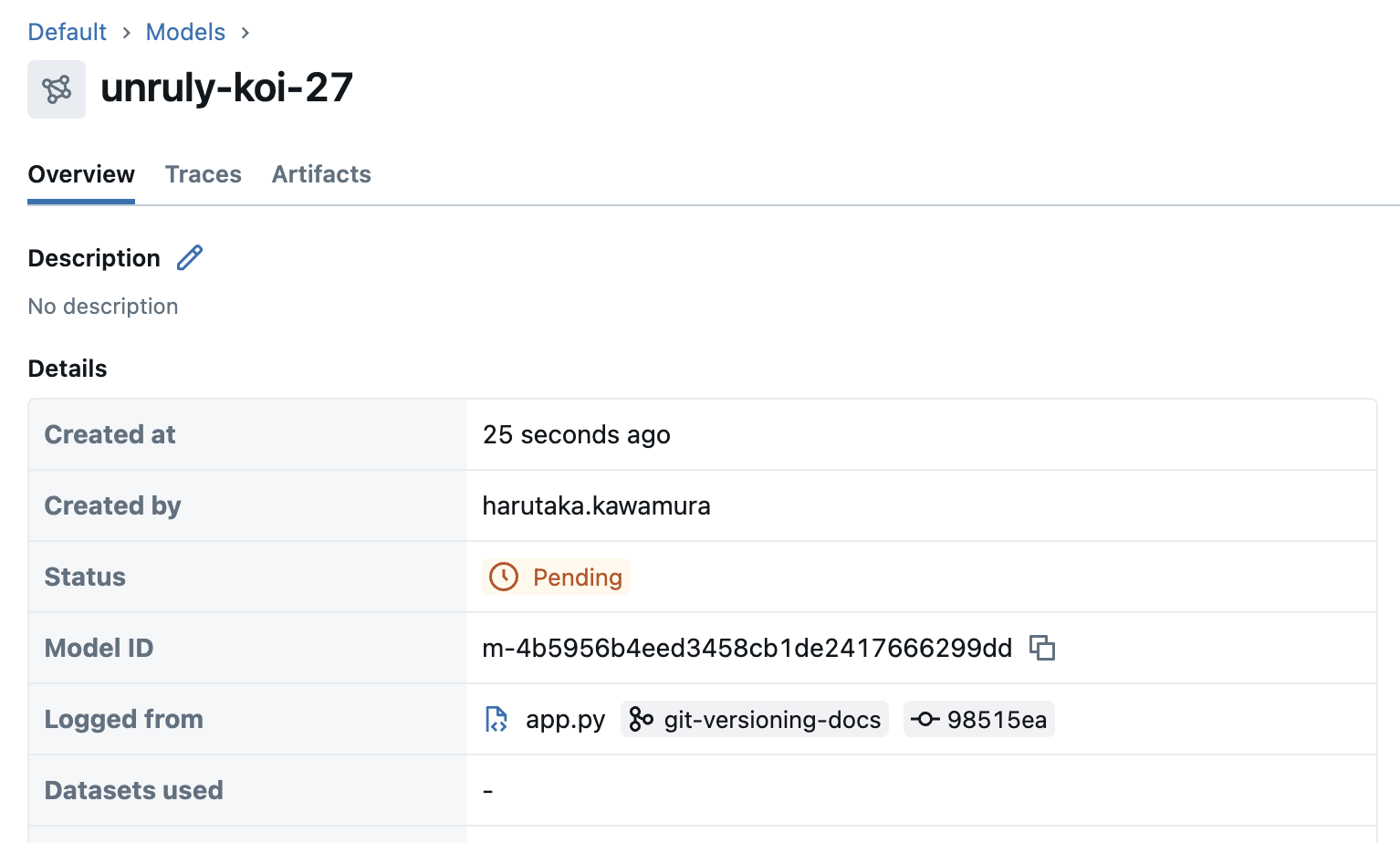
Step 5: View traces linked to the LoggedModel
Use the UI
Go to the MLflow Experiment UI. In the Traces tab, you can see the version of the app that generated each trace. In the Models tab, you can see each LoggedModel alongside its parameters and linked traces.
Use the SDK
You can use mlflow.search_traces() to query for traces from a LoggedModel:
import mlflow
# Using the context from enable_git_model_versioning()
context = mlflow.genai.enable_git_model_versioning()
traces = mlflow.search_traces(model_id=context.active_model.model_id)
print(traces)
You can use mlflow.get_logged_model() to get details of the LoggedModel including Git metadata:
import mlflow
import datetime
# Get the active Git-based version
context = mlflow.genai.enable_git_model_versioning()
# Get LoggedModel metadata
logged_model = mlflow.get_logged_model(model_id=context.active_model.model_id)
# Inspect basic properties
print(f"\n=== LoggedModel Information ===")
print(logged_model)
# Access Git metadata from tags
print(f"\n=== Git Information ===")
git_tags = {k: v for k, v in logged_model.tags.items() if k.startswith("mlflow.git")}
for tag_key, tag_value in git_tags.items():
if tag_key == "mlflow.git.diff" and len(tag_value) > 100:
print(f"{tag_key}: <diff with {len(tag_value)} characters>")
else:
print(f"{tag_key}: {tag_value}")
Next Steps
Now that you understand the basics of Git-based application versioning with MLflow, you can explore these related topics: