Building and Managing an LLM-based OCR System with MLflow




Building GenAI tools presents a unique set of challenges. As we evaluate accuracy, iterate on prompts, and enable collaboration, we often encounter bottlenecks that slow down our progress toward production.
In this blog, we explore how MLflow's GenAI capabilities help us streamline development and unlock value for both technical and non-technical contributors when building an LLM-based Optical Character Recognition (OCR) tool.
What is OCR?
Optical Character Recognition, or OCR, is the process of extracting text from scanned documents and images. The resulting text is machine-encoded, editable, and searchable, unlocking a wide range of downstream use cases.
Here, we leverage multi-modal LLMs to extract formatted text from scanned documents. Unlike traditional OCR tools such as PyTesseract, LLM-based methods offer greater flexibility for complex layouts, handwritten content, and context-aware extraction. While these methods may require more computational resources and careful prompt engineering, they provide significant advantages for advanced use cases.
Fun fact: The earliest form of OCR, the Optophone, was introduced in 1914 to help blind individuals read printed text without Braille.

The Challenge
We face several recurring challenges when building an LLM-based OCR application.
Prompt Iteration and Versioning: Prompts need to be updated and tweaked to improve extraction quality. A new prompt can introduce performance regression, but we do not save the old version. Without rigorous versioning, it's hard to roll back or compare. A prompt registry solves this by treating prompts as versioned artifacts with full change history.
Debugging Unexpected Results: Unexpected results may show up periodically in our OCR attempts. We need a way to understand why. Without detailed traceability, it is difficult to diagnose whether the issue is with the prompt, the model, or the data (e.g., a new document strucutre).
Evaluating and Comparing Models: Accuracy in OCR can mean many things. We may want to measure correct field extraction, formatting, or even business logic compliance. In order to compare different model or prompt strategies, we need a way to define and track what matters.
MLflow addresses these directly in our workflow.
OCR Use Case:
Our task is to create a document parsing tool for text extraction (OCR) using LLMs, using MLflow features to address our challenges. The data consists of scanned documents and their corresponding text extracted as JSON.
We use the FUNSD dataset, which contains around 200 fully annotated forms, structured as semantic entity labels and word groupings.
Example:

{
"form": [
{
"id": 0,
"text": "Registration No.",
"box": [94,169,191,186],
"linking": [
[0,1]
],
"label": "question",
"words": [
{
"text": "Registration",
"box": [94,169,168,186]
},
{
"text": "No.",
"box": [170,169,191,183]
}
]
},
{
"id": 1,
"text": "533",
"box": [209,169,236,182],
"label": "answer",
"words": [
{
"box": [209,169,236,182
],
"text": "533"
}
],
"linking": [
[0,1]
]
}
]
}
For a detailed description of each entry, refer to the original paper.
1. Set Up
Install the required packages:
pip install openai mlflow tiktoken aiohttp -qU
openai: For interacting with OpenAI models and APIs
mlflow: For experiment tracking, model management, and GenAI workflow tools
tiktoken: For efficient tokenization, especially useful with OpenAI models
aiohttp: For asynchronous HTTP requests, enabling efficient API calls
For this tutorial we use OpenAI, but the approach extends to other LLM providers. We can prompt the user to type the OpenAI API key without echoing using getpass():
import os
from getpass import getpass
os.environ["OPENAI_API_KEY"] = getpass("Your OpenAI API Key: ")
2. Observe the Data
Let's read a randomly selected image and its corresponding annotation JSON file. The following utils functions faciliate this task.
from __future__ import annotations
from dataclasses import dataclass
from io import BytesIO
from pathlib import Path
from typing import Any, Mapping, Sequence, TypedDict, Literal
import pandas as pd
import base64
import json
import random
import re
from PIL import Image as PILImage
DATA_DIRECTORY = Path("./data")
ANNOTATIONS_DIRECTORY = DATA_DIRECTORY / "annotations"
IMAGES_DIRECTORY = DATA_DIRECTORY / "images"
class Word(TypedDict):
text: str
class Item(TypedDict, total=False):
id: str | int
label: Literal["question", "answer", "other"]
words: list[Word]
linking: list[tuple[str | int, str | int]]
@dataclass(frozen=True)
class QAPair:
question: str
answer: str
def _flatten_form(form: Any) -> list[Item]:
"""
Flattens the 'form' section into a simple list of items.
Accepts list[Item], list[list[Item]], or a single list-like page.
"""
if isinstance(form, list):
if form and all(isinstance(page, list) for page in form):
return [item for page in form for item in page] # 2D -> 1D
return form
raise TypeError("Expected 'form' to be a list or list of lists.")
def extract_qa_pairs(items: Sequence[Mapping[str, Any]]) -> list[QAPair]:
"""
Robustly extract Q&A pairs. Supports multiple answers per question.
Does not assume unique question text; uses ids to match.
"""
by_id: dict[Any, Mapping[str, Any]] = {}
for it in items:
if "id" in it:
by_id[it["id"]] = it
pairs: list[QAPair] = []
for it in items:
if it.get("label") != "question":
continue
links = it.get("linking") or []
q_words = it.get("words") or []
q_text = " ".join(w.get("text", "") for w in q_words).strip()
for link in links:
if not isinstance(link, (list, tuple)) or len(link) != 2:
continue
q_id, a_id = link
if q_id != it.get("id"):
# Skip foreign link edges
continue
ans = by_id.get(a_id)
if not ans or ans.get("label") != "answer":
continue
a_words = ans.get("words") or []
a_text = " ".join(w.get("text", "") for w in a_words).strip()
if q_text and a_text:
pairs.append(
QAPair(
question=q_text,
answer=a_text,
)
)
return pairs
def load_annotation_file(file_name: str | Path, directory: Path = ANNOTATIONS_DIRECTORY) -> list[QAPair]:
"""
Load one annotation JSON and return extracted Q&A pairs.
Always returns a list; empty if none found.
"""
file_path = (directory / file_name) if isinstance(file_name, str) else file_name
if file_path.suffix.lower() != ".json":
file_path = file_path.with_suffix(".json")
with file_path.open("r", encoding="utf-8") as f:
data = json.load(f)
form = data.get("form")
items = _flatten_form(form)
return extract_qa_pairs(items)
def choose_random_annotation_names(
directory: Path = ANNOTATIONS_DIRECTORY,
n: int = 1,
suffix: str = ".json",
seed: int | None = None,
) -> list[str]:
"""
Returns a list of basenames (without extension). Raises if directory missing or empty.
Deterministic when seed is provided.
"""
if not directory.exists():
raise FileNotFoundError(f"Directory {directory} does not exist.")
files = sorted(p for p in directory.iterdir() if p.is_file() and p.suffix.lower() == suffix)
if not files:
raise FileNotFoundError(f"No {suffix} files found in {directory}.")
if seed is not None:
rnd = random.Random(seed)
selected = rnd.sample(files, k=min(n, len(files)))
else:
selected = random.sample(files, k=min(n, len(files)))
return [p.stem for p in selected]
def compress_image(
file_path: str | Path,
*,
quality: int = 40,
max_size: tuple[int, int] = (1000, 1000),
) -> bytes:
"""
Resize and convert to JPEG with the given quality. Returns JPEG bytes.
"""
file_path = Path(file_path)
with PILImage.open(file_path) as img:
img = img.convert("RGB")
img.thumbnail(max_size)
buf = BytesIO()
img.save(buf, format="JPEG", quality=quality, optimize=True)
return buf.getvalue()
def get_image_bytes_or_b64(
file_name: str | Path,
*,
directory: Path = IMAGES_DIRECTORY,
as_base64: bool = False,
quality: int = 40,
max_size: tuple[int, int] = (1000, 1000),
) -> bytes | str:
"""
Returns compressed JPEG bytes or a base64 string. File extension is coerced to .png on input,
but compression always outputs JPEG bytes/base64.
"""
path = (directory / file_name) if isinstance(file_name, str) else file_name
if path.suffix.lower() != ".png":
path = path.with_suffix(".png")
jpeg_bytes = compress_image(path, quality=quality, max_size=max_size)
if as_base64:
return base64.b64encode(jpeg_bytes).decode("utf-8")
return jpeg_bytes
_key_chars_re = re.compile(r"[^\w\s\-_]") # keep word chars, space, dash, underscore
_ws_re = re.compile(r"\s+")
def clean_key(key: str) -> str:
"""Remove unwanted characters, collapse whitespace, trim, and convert to UPPER_SNAKE-ish."""
key = _key_chars_re.sub("", key)
key = _ws_re.sub(" ", key).strip()
# If you prefer underscores: key = key.replace(" ", "_")
return key.upper()
def normalize_dict_keys(obj: Any) -> Any:
"""
Recursively normalize mapping keys; preserves lists/tuples;
"""
from collections.abc import Mapping as ABMapping, Sequence as ABSequence
if isinstance(obj, ABMapping):
return {clean_key(str(k)): normalize_dict_keys(v) for k, v in obj.items()}
if isinstance(obj, (list, tuple)):
return obj.__class__(normalize_dict_keys(v) for v in obj)
return obj
Let’s take a moment to break down the _extract_qa_pairs function:
- We create an ID lookup dictionary to find items by their ID
- We identify "question" items that have linked answer pair(s) in the form of (q_id, a_id)
- We construct structured QAPair objects by extracting text from both question and answer words
We can then call load_annotation_file to load an annotation JSON file and return question-answer pair (structured QAPair object).
For LLM inputs, we favor small, predictable payloads over lossless fidelity. We use get_image_bytes_or_b64 to read PNG images from a directory and convert to either compressed JPEG bytes using _compress_image or base64 depending depending on the boolean as_base64.
Bandwidth & Cost: PNG scans of forms are often 5–10× larger than a JPEG of the same resolution. Since we send images as base64 (with ≈33% overhead), shrinking bytes directly reduces request size, latency, and API cost—especially when batch-evaluating many pages.
Normalization: Converting to 8-bit RGB and flattening transparency removes PNG quirks (alpha, indexed palettes, 16-bit depth, etc.), so every image reaches the model in a consistent form. This eliminates "works on my machine" ingestion issues across providers.
Throughput Over Perfection: Our pages are high-contrast forms, so modest JPEG compression keeps text legible while dramatically shrinking files. For this tutorial, we also downscale to a max side of 1000 px, which is typically sufficient for field labels while speeding up end-to-end runs and evals.
Trade-offs & Not Converting: With tiny type, low-contrast scans, or while using classical OCR (e.g., Tesseract), we prefer lossless formats (PNG/TIFF) or use higher JPEG quality. Compression artifacts can blur thin strokes and hurt accuracy.
random_files = choose_random_annotation_names(n=1, seed=42)
image_bytes = get_image_bytes_or_b64(random_files[0], as_base64=True)
load_annotation_file(random_files[0])
3. MLflow Tracking, Autolog and Tracing
Before we make a call to OpenAI, we need to set up MLflow Tracking to ensure every experiment, prompt, and result is recorded and traceable.
We will also enable MLflow Autolog to simplify the tracking process by reducing the need for manual log statements. Below, we point MLflow to a local SQLite database as the backend store, where metrics, parameters, artifacts, and other useful information are logged automatically.
import mlflow
mlflow.set_tracking_uri("sqlite:///mlflow_runs.db")
mlflow.set_experiment("ocr-initial-experiment")
mlflow.openai.autolog()
MLflow Tracing provides us with end-to-end observability. We gain a comprehensive view of each step from prompt construction and model inference to tool calls and final outputs. If we notice various failed attemped in our OCR tool, we can use the MLflow UI to inspect traces, compare inputs and outputs, and identify whether the issue is with the prompt, the model, or the data structure
In order to access the MLflow UI, we need to run the following. The UI will start on http://localhost:5000 by default:
mlflow ui --backend-store-uri sqlite:///mlflow_runs.db

4. Loading inputs and Prompting
We start by defining a system prompt for extracting the contents of the images into lists of "questions" and "answers" using an LLM. We will use a "first pass" prompt, deliberately made short and minimally descriptive so that subsequent improvements can be made later on. These are tracked under the MLflow experiment runs when the LLM completion calls are invoked for each image file. We convert the QAPair object into a dictionary for easier comparison with the LLM response during evaluation.
from collections import defaultdict
_files = choose_random_annotation_names(n=5, seed=42)
#Store multiple answers per question as list
annotation_items = []
for file_name in _files:
file_dict = defaultdict(list)
for pair in load_annotation_file(file_name):
file_dict[pair.question].append(pair.answer)
annotation_items.append(dict(file_dict))
annotation_normalized = normalize_dict_keys(annotation_items)
images = [get_image_bytes_or_b64(file, as_base64=True) for file in _files]
system_prompt = """You are an expert at Optical Character Recognition (OCR). Extract the questions and answers from the image."""
5. Setting up the LLM
On the OpenAI side, we initialize the client and send a prompt to the LLM, instructing it to act as an OCR expert. The expected output is a Structured Output containing a list of key-value pairs. To enforce this structure, we can define Pydantic models that validate the response format. Let's try to invoke the LLM and log the execution and see what the response looks like.
from pydantic import BaseModel
from openai import OpenAI
# Define Pydantic models for structured output in the form of key-value pair accounting for duplicate questions
class KeyValueModel(BaseModel):
key: str
value: list[str]
class KeyValueList(BaseModel):
pairs: list[KeyValueModel]
client = OpenAI()
def get_completion(inputs: str) -> str:
completion = client.chat.completions.parse(
model="gpt-4o-mini",
response_format=KeyValueList,
messages=[
{"role": "system", "content": system_prompt},
{
"role": "user",
"content": [
{ "type": "text", "text": "what's in this image?" },
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{inputs}",
},
},
],
}
],
)
generated_response = {pair.key: pair.value for pair in completion.choices[0].message.parsed.pairs}
return normalize_dict_keys(generated_response)
with mlflow.start_run() as run:
predicted = get_completion(images[0])
print(predicted)
The following screenshot represents the extracted questions and answers for this specific image.

Prompt Registry
Prompt engineering is central to LLM-based OCR, but creating an initial prompt is often not sufficient. In order to track which prompt version produced which results as we iterate, we will use MLflow Prompt Registry. This allows us to register, version, and add tags to prompts.
Here's an example of a prompt template, specifically instructing the LLM to generate results in our expected format.
new_template = """You are an expert at Optical Character Recognition (OCR). Extract the questions and answers from the image as a JSON object, where the keys are questions and the values are answers. If there are no questions or answers, return an empty JSON object {}.
"""
This initial prompt can be registered along with a prompt name, commit message, and relevant tags. Once registered, it can later be retrieved using mlflow.genai.load_prompt() for reuse or further improvements.
# Register a new prompt for OCR question-answer extraction
new_prompt = mlflow.genai.register_prompt(
name="ocr-question-answer",
template=new_template,
commit_message="Initial commit",
tags={
"author": "author@example.com",
"task": "ocr",
"language": "en",
},
)
prompt = mlflow.genai.load_prompt(name_or_uri="ocr-question-answer", version=new_prompt.version)
system_prompt = prompt.template
6. Defining and Evaluating Performance
As ML engineers, we ensure that the OCR application using the LLM is robustly evaluated against ground truth. When evaluating an OCR system, we care about more than just accuracy. We may look at format compliance, business logic, or field extraction results. MLflow Evaluate allows us to define built-in and custom metrics that align with our use case.
While MLflow supports LLM-as-a-judge metrics, for this OCR example it's better and cheaper to use deterministic metrics. For example, we can define a custom metric key_value_accuracy to check if key-value pair of the generated output correctly matches that of the ground truth.
from mlflow.metrics.base import MetricValue
from mlflow.models import make_metric
def batch_completion(df: pd.DataFrame) -> pd.Series:
result = [get_completion(image) for image in df["inputs"]]
return pd.Series(result)
def key_value_accuracy(predictions: pd.Series, truth: pd.Series) -> MetricValue:
"""
Calculate accuracy scores by comparing predicted dictionaries with ground truth dictionaries.
Both predictions and truth are expected to be dict[str, list[str]] format.
"""
scores = []
for pred_dict, truth_dict in zip(predictions, truth):
if not isinstance(pred_dict, dict) or not isinstance(truth_dict, dict):
scores.append(0.0)
continue
correct = 0
total_answers = 0
for question, truth_answers in truth_dict.items():
total_answers += len(truth_answers)
if question in pred_dict:
pred_answers = pred_dict[question]
# Count how many truth answers are correctly predicted
for truth_ans in truth_answers:
if truth_ans in pred_answers:
correct += 1
scores.append(correct / total_answers if total_answers > 0 else 0.0)
return MetricValue(
scores=scores,
aggregate_results={
"mean": sum(scores) / len(scores) if scores else 0.0,
"p90": sorted(scores)[int(len(scores) * 0.9)] if scores else 0.0
}
)
custom_key_value_accuracy = make_metric(
eval_fn=key_value_accuracy,
greater_is_better=True,
name="key_value_accuracy",
)
After defining this custom metric, we can evaluate it over a dataframe, which includes a subset of base64-encoded images and their corresponding ground truth dictionaries. Using the batch_completion function, we run a batch completion request on this subset, retrieving outputs in the predefined Structured Output format.
results = mlflow.models.evaluate(
model=batch_completion,
data=pd.DataFrame({"inputs": images, "truth": annotation_normalized}),
targets="truth",
model_type="text",
predictions="predictions",
extra_metrics=[custom_key_value_accuracy]
)
print("Custom metric results:", results.metrics)
eval_table = results.tables["eval_results_table"]
print("\n Per-row scores:")
print(eval_table[['key_value_accuracy/score']])
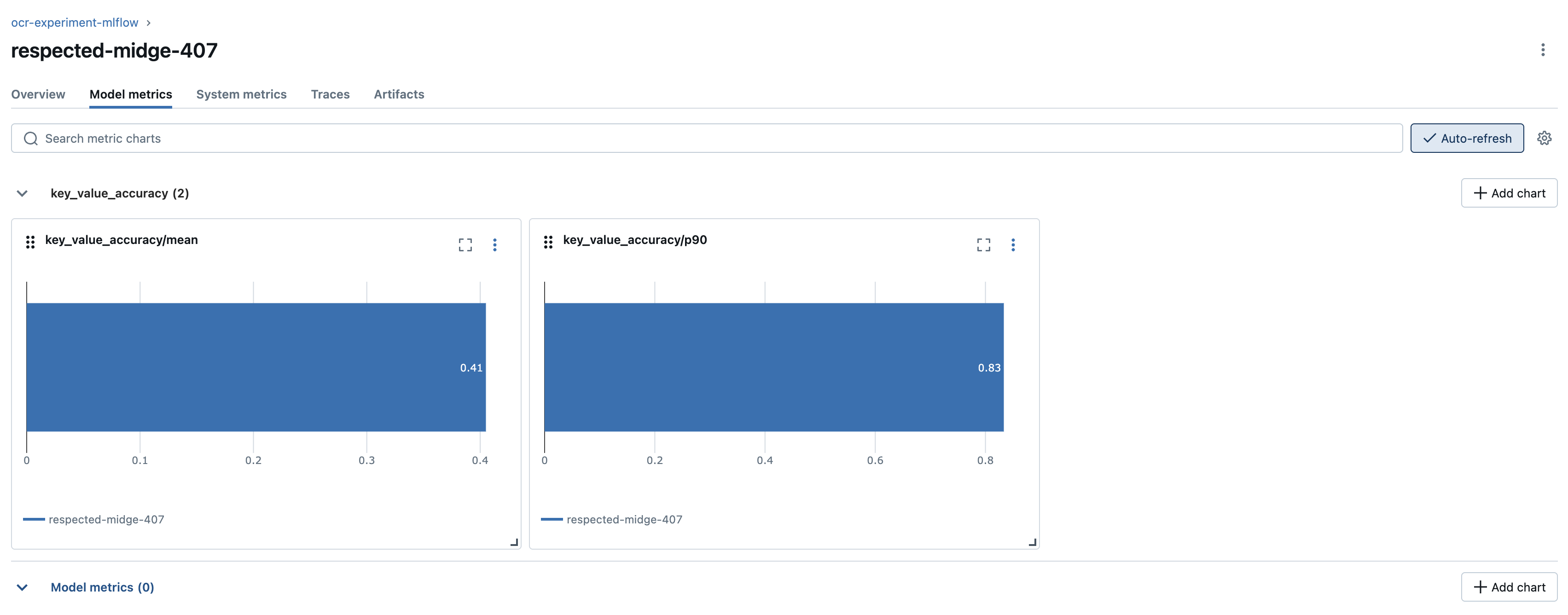
This metric requires an exact match between the key-value pairs in the ground truth and the LLM-generated output. Upon reviewing the individual scores for each image, we observe that the model performs the worst on the last image. Specifically, one of the keys is incorrectly generated as CHAINS - ACCEPTANCEMERCHANDISING instead of CHAINS ACCEPTANCE/ MERCHANDISING. A similar pattern can be observed in other keys where different topics are improperly separated or unnecessarily paraphrased.
To address this, we can refine the prompt template by explicitly instructing the model to separate distinct topics using the / separator. Additionally, we can instruct the LLM to avoid paraphrasing the topics in the keys and instead focus on maintaining exactness to the image text.
updated_template = """\
You are an expert at key information extraction and OCR. Extract the questions and answers from the image, where the keys are questions and the values are answers.
Question refers to a field in the form that takes in information. Answer refers to the information
that is filled in the field.
Follow these rules:
- Only use the information present in the text and do not paraphrase.
- If the keys have multiple topics, separate them with a slash (/)
{{ additional_rules }}
"""
The next step is to register the updated prompt template, load it back later and format it with any additional rule before rerunning the evaluation.
updated_prompt = mlflow.genai.register_prompt(
name="ocr-question-answer",
template=updated_template,
commit_message="Update commit",
tags={
"author": "author@example.com",
"task": "ocr",
"language": "en",
},
)
# Load the updated prompt and format it with additional rules
prompt = mlflow.genai.load_prompt(name_or_uri="ocr-question-answer", version=updated_prompt.version)
system_prompt = prompt.format(additional_rules="Use exact formatting you see in the form.")
results_updated = mlflow.models.evaluate(
model=batch_completion,
data=pd.DataFrame({"inputs": images, "truth": annotation_normalized}),
targets="truth",
model_type="text",
predictions="predictions",
extra_metrics=[custom_key_value_accuracy]
)
print("Custom metric results:", results_updated.metrics)
eval_table_updated = results_updated.tables["eval_results_table"]
print("\n Per-row scores:")
print(eval_table_updated[['key_value_accuracy/score']])
This updated prompt may lead to a marginal improvement in the metric for each image. However, there are still mismatches in values between the ground truth and the LLM response. As showcased above using Prompt Registry, iteratively refining the prompt can address these issues, leading to better alignment with the expected output.
Conclusion and Next Steps
By leveraging MLflow GenAI capabilities, we efficiently manage prompts and evaluate models for our OCR tool. With all runs, prompts, and metrics logged, we can compare different models or prompt strategies side-by-side in the MLflow UI. This enables data-driven decisions, justifies model selection, and enables both technical and non-technical contributors to collaborate, iterate, and deploy AI solutions confidently.
We can take several directions to further enhance our workflow and outcomes:
Expand Your Custom Metrics: Scale out your custom evaluation metrics to more accurately capture the requirements of our specific OCR problem. This allows us to measure what truly matters for the use case, such as domain-specific accuracy, formatting compliance, or business logic adherence.
Experiment with Multiple LLMs: Take advantage of MLflow’s ability to track and compare experiments by iterating with different LLMs. We can view and analyze results side-by-side in the MLflow UI, making it easier to identify which model best fits our needs and to justify model selection with clear, data-driven evidence.
Utilize Tracing and Model Logging: Leverage MLflow’s tracing and model logging features to gain end-to-end visibility into our GenAI workflows. By capturing detailed traces and logs, we can iteratively refine our models and prompts, diagnose issues, and ensure reproducibility—all within the context of our custom metrics.
Expand Governance and Access Control: Implement robust governance practices to ensure secure, compliant, and auditable management of our GenAI assets and workflows. This is especially important for scaling in enterprise or regulated environments.
These are just a few of the many ways we can build on this solution. Whether we are aiming to improve model performance, streamline collaboration, or scale our solution to new domains, these MLflow capabilities support us in our GenAI development.
Further Reading
Practical AI Observability: Getting Started with MLflow Tracing
Beyond Autolog: Add MLflow Tracing to a New LLM Provider
LLM as Judge