Bring Your Own Prompts
The custom_prompt_judge API is being phased out. We strongly recommend using the make_judge API instead, which provides:
- More flexible template-based instructions
- Better version control and collaboration features
- Support for both field-based and Agent-as-a-Judge evaluation
- Alignment capabilities with human feedback
See the make_judge documentation for migration guidance.
The custom_prompt_judge API is designed to help you quickly and easily create LLM scorers when you need full control over the judge's prompt or need to return multiple output values beyond "pass" / "fail", for example, "great", "ok", "bad".
You provide a prompt template that has placeholders for specific fields in your app's trace and define the output choices the judge can select. The LLM judge model uses these inputs to select the best output choice and provides a rationale for its selection.
We recommend starting with guidelines-based judges and only using prompt-based judges if you need more control or can't write your evaluation criteria as pass/fail guidelines. Guidelines-based judges have the distinct advantage of being easy to explain to business stakeholders and can often be directly written by domain experts.
Example Usage
from mlflow.genai.judges import custom_prompt_judge
from mlflow.genai.scorers import scorer
issue_resolution_prompt = """
Evaluate the entire conversation between a customer and an LLM-based agent. Determine if the issue was resolved in the conversation.
You must choose one of the following categories.
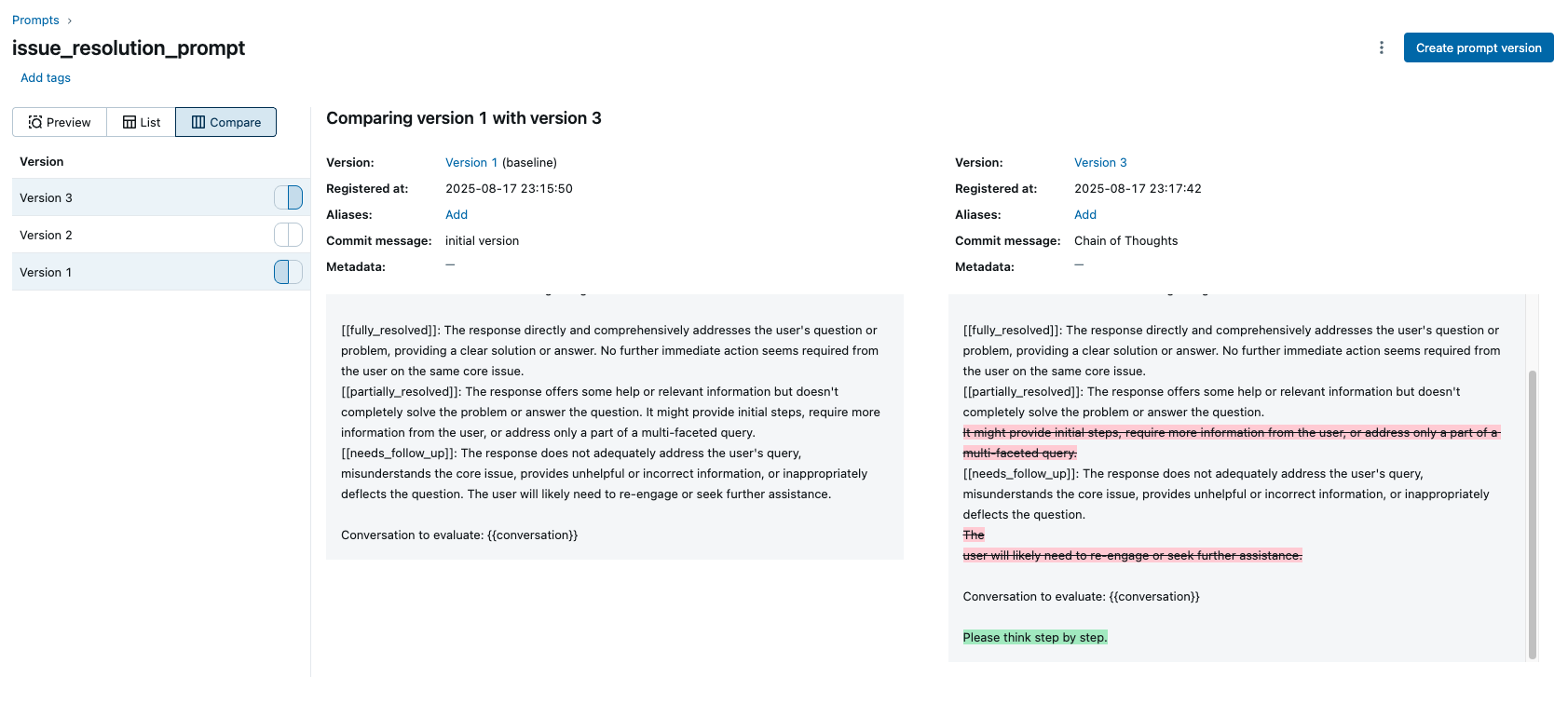
[[fully_resolved]]: The response directly and comprehensively addresses the user's question or problem, providing a clear solution or answer. No further immediate action seems required from the user on the same core issue.
[[partially_resolved]]: The response offers some help or relevant information but doesn't completely solve the problem or answer the question. It might provide initial steps, require more information from the user, or address only a part of a multi-faceted query.
[[needs_follow_up]]: The response does not adequately address the user's query, misunderstands the core issue, provides unhelpful or incorrect information, or inappropriately deflects the question. The user will likely need to re-engage or seek further assistance.
Conversation to evaluate: {{conversation}}
"""
# Define a custom scorer that wraps the custom prompt judge to check if the issue was resolved
@scorer
def is_issue_resolved(inputs, outputs):
issue_judge = custom_prompt_judge(
name="issue_resolution",
prompt_template=issue_resolution_prompt,
# Optionally map the categories to numeric values for ease
# of aggregation and comparison. When not provided, the judge
# directly returns the choice value as a string.
numeric_values={
"fully_resolved": 1,
"partially_resolved": 0.5,
"needs_follow_up": 0,
},
)
# Pass values for the placeholders ({{conversation}}) as kwargs
conversation = inputs["messages"] + outputs["messages"]
return issue_judge(conversation=conversation)
Prompt requirements
The prompt template for the judge must have:
- Placeholders for input values with double curly braces, e.g.,
{{conversation}}. - Choices for the judge to select from as output, enclosed in square brackets, e.g.,
[[fully_resolved]]. The choice name can contain alphanumeric characters and underscores.
MLflow uses raw prompt-based instructions for handling structured outputs to make the API generic to all LLM providers. This may not be strict enough to enforce structured outputs in all cases. If you see output parsing errors frequently, consider using code-based custom scorers and invoke the specific structured output API for the LLM provider you are using to get more reliable results.
Maintaining Your Prompt
Writing good prompts for LLM judges requires iterative testing and refinement. MLflow Prompt Registry is a great tool to help you manage and version control your prompts and share them with your team.
from mlflow.genai import register_prompt
register_prompt(
name="issue_resolution",
template=issue_resolution_prompt,
)
Selecting Judge Models
MLflow supports all major LLM providers, such as OpenAI, Anthropic, Google, xAI, and more. See Supported Models for more details.
from mlflow.genai.judges import custom_prompt_judge
custom_prompt_judge(
name="is_issue_resolved",
prompt_template=issue_resolution_prompt,
model="anthropic:/claude-3-opus",
)
Next Steps
Evaluate Agents
Learn how to evaluate AI agents with specialized techniques and scorers
Prompt Registry
Version control and manage your judge prompts with MLflow Prompt Registry
Collect User Feedback
Integrate user feedback to continuously improve your evaluation criteria and model performance